
《本地LLM神器Ollama,浏览器就能玩转AI!》
超过 1 年前
使用 Ollama 与 Browser-Use 来利用本地大语言模型(LLMs)
引言
在本文中,我们将展示如何通过在 Browser-Use 的网页界面中选择 Ollama 作为提供者来使用本地大语言模型(LLMs)。截至 2025 年 1 月 12 日,Browser-Use 网页界面允许你从多个 LLM 提供者中选择,包括 Anthropic、OpenAI、DeepSeek、Gemini、Ollama 和 Azure OpenAI。使用 Ollama 可以避免 API 费用,因此它是实验本地 LLMs 的一个绝佳选择。
本文将指导你如何设置并使用 Browser-Use 与 Ollama。
什么是 Browser-Use?
Browser-Use 是一个利用 AI 代理自动化浏览器操作的库。
官方仓库:Browser-Use GitHub
其示例目录提供了多种使用场景:Browser-Use 示例
Browser-Use 网页界面
Browser-Use 网页界面允许你通过网页界面与 Browser-Use 进行交互。
克隆仓库:
git clone git@github.com:browser-use/web-ui.git
你需要 Python 3.11 或更高版本。设置虚拟环境并安装所需的包:
pyenv install 3.11
pyenv local 3.11
python -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
playwright install
设置环境变量:
cp .env.example .env
启动网页界面:
python webui.py --ip 127.0.0.1 --port 7788
使用 Ollama 的本地 LLMs
下载 Ollama
首先,下载 Ollama。
下载后安装 Ollama。
安装所需的模型
接下来,通过 Ollama 安装必要的模型。截至 2025 年 1 月 12 日,Browser-Use 网页界面支持 “qwen2.5:7b” 和 “llama2:7b” 作为 Ollama 的默认模型。你也可以指定自定义模型。
安装模型:
ollama run qwen2.5:7b
ollama run llama2:7b
更多关于这些模型的详细信息:
配置 Browser-Use 网页界面
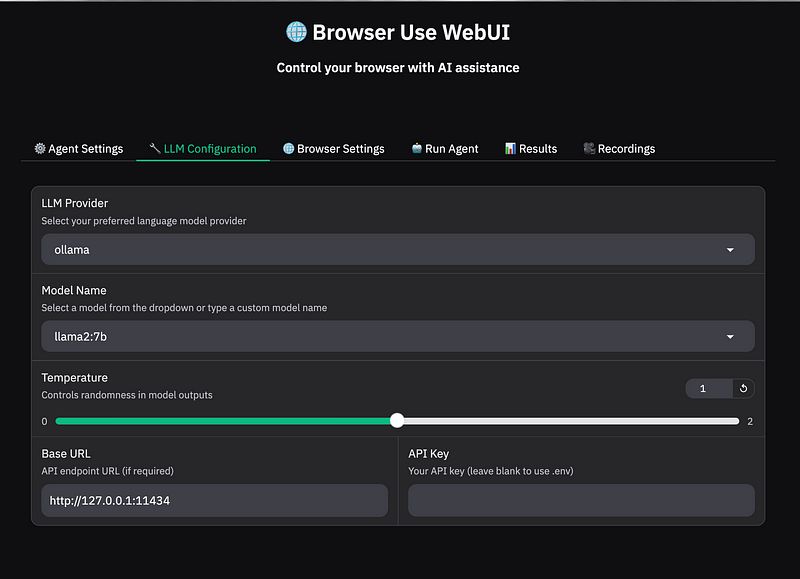
在 LLM 配置 标签中:
- 选择 “Ollama” 作为 LLM 提供者。
- 选择 “llama2:7b” 作为模型名称。
- 将基础 URL 设置为 Ollama 的端点:
http://127.0.0.1:11434。
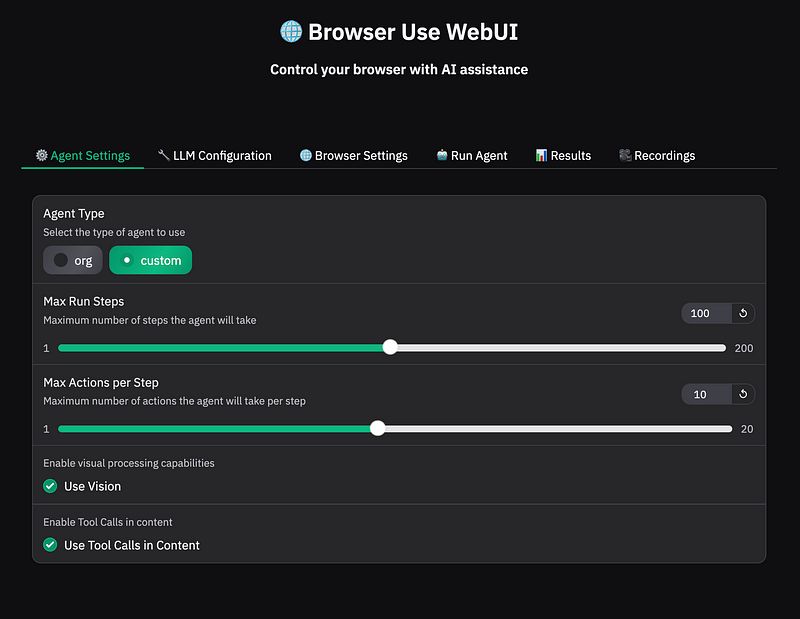
在 代理设置 下,取消勾选 “使用视觉” 和 “在内容中使用工具调用”。
最后,在 运行代理 标签中,提供任务描述并点击 “运行代理”。
实际示例
访问 Google 并检索 “OpenAI” 的第一个 URL
从 Browser-Use 网页界面提供的默认任务描述开始:
go to google.com and type 'OpenAI' click search and give me the first url
使用本地 LLMs 时,任务耗时显著长于使用 OpenAI 的 gpt-4o。以下是详细情况:
llama2:7b到达了第 5 步,但最终失败。qwen2.5:7b到达了第 4 步,同样失败。
每个任务耗时大约 10-20 分钟。
为了提高速度,可以安装一个较小的模型,如 gemma:2b:
ollama run gemma:2b
更新 LLM 配置:
- 将 LLM 提供者设置为 “Ollama”。
- 输入 “gemma:2b” 作为模型名称。
使用 gemma:2b 时,每个步骤耗时 30 秒到 1 分钟,但任务仍然失败。
结论
在本文中,我们展示了如何通过将 Ollama 与 Browser-Use 的网页界面集成来利用本地 LLMs。使用本地 LLMs 可以让你在不产生 API 费用的情况下实验浏览器自动化。
虽然在我们的测试中任务没有成功完成,但我们验证了本地 LLMs 确实可以与 Browser-Use 一起使用。
感谢阅读!希望本文对你有所帮助。
推荐阅读:




FluxAI 中文
© 2026. All Rights Reserved