
在运行 Linux Mint Wilma(基于 Ubuntu)的旧款 Nvidia 1080 Ti 电脑上测试 Forge(稳定扩散 Flux)
超过 1 年前
在旧款 Nvidia 1080 Ti PC 上测试 Forge(稳定扩散 Flux)
运行 Linux Mint Wilma(Ubuntu 24.04 LTS),使用 Python 3.12、Python 3.11、Python 3.10 和 Xformers。
Flux 模型和 SDXL 模型都是 AI 生成图像的重要创新,特别是在 稳定扩散 框架内。它们的差异和优势主要与模型的架构、效率和预期用途相关。让我们仔细看看:(与 ChatGPT4o 一起)
1. Flux 模型(稳定扩散 XL Flux):
Flux 是开发图像生成模型的新趋势之一,经过某些增强优化,基于稳定扩散模型。
优势:
- 提高效率:Flux 模型设计为比 SDXL 模型计算更轻。这使得它们在需要更快性能或较低硬件要求的环境中非常有用。
- 较低资源消耗:当 GPU 资源有限或希望在不太强大的硬件上优化模型使用时,Flux 可以提供帮助。
- 简化的架构优化:Flux 模型可能利用某些优化,例如减少扩散步骤或增强精炼过程,从而在特定任务中实现更快的生成。
- 使用场景:Flux 模型非常适合快速原型设计、早期项目草图或需要更快响应时间的交互式实时应用。
2. SDXL 模型(稳定扩散 XL):
SDXL 是稳定扩散模型的更大、更复杂的版本,专注于高分辨率图像生成和改善图像质量。
优势:
- 增强细节和质量:SDXL 模型显著更大,能够生成比传统模型更详细的图像。由于参数更多,它们可以创建更复杂和逼真的图像。
- 高分辨率输出:SDXL 特别适合生成大型和详细的图像,因为它处理更广泛的数据量,并更仔细地优化图像特征。
- 先进的多算法架构:该模型采用先进技术来提高图像细节的准确性,特别是在细节、光照和色彩管理等领域。
- 使用场景:SDXL 适合于高质量和详细图像至关重要的项目,例如商业项目、艺术制作以及任何需要高视觉保真度的地方。
比较与总结:
- 效率与质量:Flux 模型优化了效率和速度,而 SDXL 模型则专注于图像质量和细节精度。
- 硬件要求:SDXL 需要更多的计算能力和 GPU 内存,因此 Flux 模型可能更适合资源有限的设置。
- 预期用途:Flux 模型非常适合快速草图和轻量级图像生成需求,而 SDXL 则在追求高质量、详细图像时表现出色。
这两种模型各有其优势,适用于不同的优先事项(速度、质量、资源)。
评论:这个总结是由 ChatGPT 制作的,可能并不准确。请阅读 这篇文章 以获取更多信息。
如果你不想等待 Automatic1111 Flux 更新,可以使用 Forge,它非常相似。我想测试一下是否可以在我的旧测试 PC(Nvidia 1080 Ti)上运行 Forge,并验证 Flux 是否比 SDXL 更快。这个测试主要是一个学习经验,我在每个主题的末尾标记了关键的学习点。
与 Automatic1111 相比,Forge 的速度似乎更慢,即使使用 SDXL 模型,尽管可以使用 Xformers 来提升 Forge 的性能。
以下是我进行的测试,以及我设置虚拟环境、从 GitHub 克隆 Forge 并使其正常工作的步骤,首先使用不受支持的 Python 3.12,然后是 Python 3.11,最后是受支持的 Python 3.10。我还测试了 Xformers,但不幸的是,未能提高性能。
注意: 如果你有 Python 3.10 或 Python 3.11,可以使用命令 python3.10 -m venv venv 创建虚拟环境,并跳过下面的 Python 3.12 部分。
Python 3.12
让我们在 /opt/forge 创建虚拟环境:
sudo mkdir /opt/forge
sudo chown yourname:yourgroup /opt/forge
cd /opt/forge
python3 -m venv venv
source venv/bin/activate
git clone https://github.com/lllyasviel/stable-diffusion-webui-forge.git
cd stable-diffusion-forge
./webui.sh
由于 Ubuntu 24.04 LTS 和 Mint Wilma 自带 Python 3.12,我们看到这个提示:
不兼容的 Python 版本
该程序已在 3.10.6 Python 上测试,但你使用的是 3.12.3。如果你遇到 "RuntimeError: Couldn't install torch." 的错误消息,或任何其他与未成功安装包(库)相关的错误,请降级(或升级)到最新版本的 3.10 Python,并删除 WebUI 目录中的当前 Python 和 "venv" 文件夹。
如预期,使用 Python 3.12 安装最终导致错误:
为 Pillow 构建 wheel(pyproject.toml):状态为 'error'
错误:无法为 Pillow 构建 wheels,这是安装基于 pyproject.toml 的项目所必需的。
让我们尝试通过更新 Pillow 来解决这个问题:
sudo apt-get install libjpeg-dev zlib1g-dev
Pillow 更新现在也导致错误:
RuntimeError: 无法导入 diffusers.pipelines.pipeline_utils,因为以下错误(查看上面的回溯):无法导入 diffusers.models.autoencoders.autoencoder_kl,因为以下错误(查看上面的回溯):没有名为 'distutils' 的模块。
主要问题:
无效的转义序列
(:警告提到在文件/opt/forge/stable-diffusion-webui-forge/modules/prompt_parser.py:387中存在无效的转义序列。这可能是由于 Python 字符串字面量中的字符未正确转义造成的。要解决此问题,可以将(替换为\(,或通过在字符串前加上r"..."来使用原始字符串,以避免 Python 解释转义序列。ModuleNotFoundError: 没有名为 'distutils' 的模块:- 这是导致失败的主要问题。
distutils模块在你的 Python 环境中缺失。它是一个用于实用函数的遗留模块,例如strtobool在distutils.util中。 - Python 3.12 不再默认包含
distutils作为标准库的一部分,因为它已被弃用并最终删除。
- 这是导致失败的主要问题。
好的,distutils 不受支持,让我们通过更新 setuptools 到合适的版本来解决 distutils 问题:
python -m pip install --upgrade setuptools
然后再次启动 ./webui.sh,现在 Forge 似乎正常加载。
如果你遇到 insightface 问题,请执行以下操作:
pip install protobuf==3.20.0
pip install protobuf==4.25.3
pip install insightface
pytorch 版本:2.3.1+cu121 设备:cuda:0 NVIDIA GeForce GTX 1080 Ti: 本地 … [GPU 设置] 你将使用 90.82% 的 GPU 内存(10133.00 MB)来加载权重,并使用 9.18% 的 GPU 内存(1024.00 MB)进行矩阵计算。你没有任何模型!选择的模型: {'checkpoint_info': None, 'additional_modules': [], 'unet_storage_dtype': None} 使用在线 LoRAs 在 FP16:False
所以,现在 Forge 后端和前端似乎正常加载。
让我们看看能否用 Flux 创建一些图片。为此,我们需要下载一个 Flux 模型。从 HuggingFace 链接 下载最新的模型文件,今天是 flux1-dev-bnb-nf4-v2.safetensors(12GB),并将其保存到 /opt/forge/stable-diffusion-webui-forge/models/Stable-diffusion 文件夹中。
注意!使用 Nvidia 1080Ti NF4 不是选项,你必须下载 https://huggingface.co/lllyasviel/flux1_dev/blob/main/flux1-dev-fp8.safetensors!(我昨天不知道这一点)。
提示:NF4 指的是 4 位非浮点精度,BNB 代表 BitsandBytes,是一种低位加速器模型,而 GGUF 是一种优化用于快速加载和保存模型的二进制格式。
第一次生成非常慢。我使用默认启动参数,Euler(简单),20 步,3.5 CFG 和大小 896x1152。生成耗时 12:15 分钟,但没有错误:
所有加载到 GPU。总进度: 100%|████████████████████████████████████████████████████████████████████████████████████| 20/20 [12:15<00:00, 37.11s/it]

使用 Forge Flux 和 Python3.12 制作的第一张图片。
所以,Forge 在 Python3.12 上工作,但速度问题与 Python 版本有关吗?
学习到的经验:
- Python3.12 可以工作,但使用旧版本可能更简单。
- Nvidia 1080 Ti 不支持 NF4,因此,实际上我应该使用 https://huggingface.co/lllyasviel/flux1_dev/blob/main/flux1-dev-fp8.safetensors(17GB)。
Python 3.11 和 xformers
让我们删除 venv,使用 Python3.11,它在 Automatic1111 中运行良好,也应该适用于 Forge:
cd ..
deactivate
rm -rf venv
python3.11 -m venv venv
source venv/bin/activate
./webui.sh
安装没有错误结束。
后端启动没有 Python3.10 的要求通知,假设 Python3.11 是可以的,如预期。
让我们使用提示创建一些东西:“艾玛·史东穿着肚皮舞者的肖像,阿拉伯之夜,高质量,完全详细,4K,聚焦清晰的面部,细致的手部细节和解剖结构,灵感来自 YouTube 上的肚皮舞者夏奇拉,由 artgerm 和 greg rutkowski 以及阿尔丰斯·穆夏创作,杰作,惊艳,artstation”。
使用默认启动参数(Euler 简单,20 步):
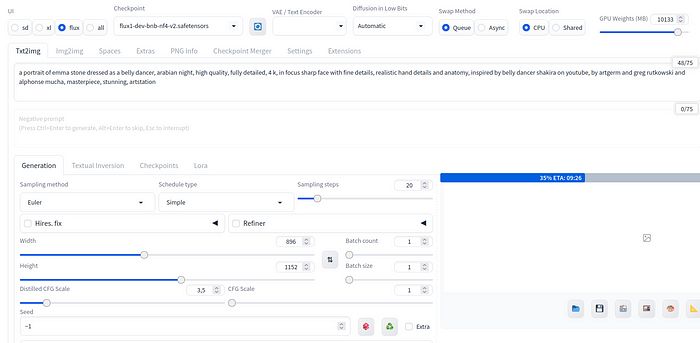
使用 Python3.11 的 Forge。
生成仍然很慢,12:08 分钟,可能与 Python 版本无关。
所有加载到 GPU。总进度: 100%|████████████████████████████████████████████████████████████████████████████████████| 20/20 [12:08<00:00, 36.44s/it]

使用 Forge Flux 和 Python3.11 制作的第二张图片。
也许安装 xformers 可以加快速度?让我们试试。
source venv/bin/activate
pip install xformers
安装卸载了 triton、cuda、torch,抱怨 protobuf 版本太新,然后尝试安装时出错:
错误:pip 的依赖解析器当前未考虑所有已安装的包。这种行为是以下依赖冲突的来源。 open-clip-torch 2.20.0 需要 protobuf<4,但你有 protobuf 4.25.5,这不兼容。 torchvision 0.18.1+cu121 需要 torch==2.3.1,但你有 torch 2.4.1,这不兼容。
pip check
xformers 0.0.28.post1 需要 torch==2.4.1,但你有 torch 2.3.1。
pip install torch==2.4.1
pip check
现在 torchvision 0.18.1+cu121 需要 torch==2.3.1,但你有 torch 2.4.1。
pip install torch==2.3.1
现在我遇到了 xformers 错误 :)
在 torch、torchvision 和 xformers 的版本之间存在循环依赖冲突。让我们进一步看看:
torchvision需要torch==2.3.1。xformers需要torch==2.4.1。- 安装的
torch版本可能不符合这些要求。
好的,让我们先卸载这两个:
pip uninstall torch torchvision xformers
然后启动 Forge,使用 ./webui.sh,这将再次安装所需的包,然后再次尝试安装 xformers。
Pip 显示了一些关于不兼容的提示,但成功安装了 nvidia-cudnn-cu12–9.1.0.70 torch-2.4.1 triton-3.0.0 xformers-0.0.28.post1。
让我们看看再次执行 ./webui.sh 会发生什么。
现在崩溃了:
WARNING:xformers:WARNING[XFORMERS]: xFormers 无法加载 C++/CUDA 扩展。xFormers 是为:PyTorch 2.4.1+cu121 和 CUDA 1201 构建的(你有 2.3.1+cu121)Python 3.11.10(你有 3.11.10)请重新安装 xformers(见 https://github.com/facebookresearch/xformers#installing-xformers)内存高效注意力、SwiGLU、稀疏等将不可用。设置 XFORMERS_MORE_DETAILS=1 以获取更多详细信息。
RuntimeError: 无法导入 diffusers.pipelines.pipeline_utils,因为以下错误(查看上面的回溯):无法导入 diffusers.models.autoencoders.autoencoder_kl,因为以下错误(查看上面的回溯):模块 'torch.library' 没有属性 'custom_op'。
好的,xformers 有问题,让我们卸载 xformers 并安装 cu124 版本:
pip3 install -U xformers --index-url https://download.pytorch.org/whl/cu124
现在结果看起来更好:
成功安装 nvidia-cublas-cu12–12.4.2.65 nvidia-cuda-cupti-cu12–12.4.99 nvidia-cuda-nvrtc-cu12–12.4.99 nvidia-cuda-runtime-cu12–12.4.99 nvidia-cufft-cu12–11.2.0.44 nvidia-curand-cu12–10.3.5.119 nvidia-cusolver-cu12–11.6.0.99 nvidia-cusparse-cu12–12.3.0.142 nvidia-nvjitlink-cu12–12.4.99 nvidia-nvtx-cu12–12.4.99 torch-2.4.1+cu124 triton-3.0.0 xformers-0.0.28.post1。
让我们看看执行 ./webui.sh 的结果:
pytorch 版本:2.4.1+cu124 xformers 版本:0.0.28.post1 设置 vram 状态为:NORMAL_VRAM 设备:cuda:0 NVIDIA GeForce GTX 1080 Ti:本地 VAE dtype 偏好:[torch.float32] -> torch.float32 使用 xformers 交叉注意力 使用 xformers 注意力用于 VAE。
错误:AttributeError: 部分初始化的模块 'torchvision' 没有属性 'extension'(很可能是由于循环导入)。
pip check
mediapipe 0.10.15 需要 protobuf<5,>=4.25.3,但你有 protobuf 3.20.0。onnx 1.17.0 需要 protobuf>=3.20.2,但你有 protobuf 3.20.0。torchvision 0.18.1+cu121 需要 torch==2.3.1,但你有 torch 2.4.1+cu124。
pip install mediapipe --upgrade
pip install protobuf==3.20.2
pip install torchvision==0.19.0
成功安装 nvidia-cublas-cu12–12.1.3.1 nvidia-cuda-cupti-cu12–12.1.105 nvidia-cuda-nvrtc-cu12–12.1.105 nvidia-cuda-runtime-cu12–12.1.105 nvidia-cufft-cu12–11.0.2.54 nvidia-curand-cu12–10.3.2.106 nvidia-cusolver-cu12–11.4.5.107 nvidia-cusparse-cu12–12.1.0.106 nvidia-nvtx-cu12–12.1.105 torch-2.4.0 torchvision-0.19.0。
现在 pip check 报告 mediapipe 和 xformers 的问题:
mediapipe 0.10.15 需要 protobuf<5,>=4.25.3,但你有 protobuf 3.20.2。xformers 0.0.28.post1 需要 torch==2.4.1,但你有 torch 2.4.0。
但现在 Forge 可以正常启动并使用 xformers:
Python 3.11.10(主,2024年9月7日,18:35:41)[GCC 13.2.0] 版本: f2.0.1v1.10.1-previous-569-g6dc71b7e pytorch 版本:2.4.0+cu121 xformers 版本:0.0.28.post1 设备:cuda:0 NVIDIA GeForce GTX 1080 Ti:本地 使用 xformers 交叉注意力 使用 xformers 注意力用于 VAE。
让我们再次使用默认启动参数进行测试(Euler 简单):
提示:中世纪的哈莉·奎因和小丑,肖像,顽皮,幻想,中世纪,美丽的面孔,鲜艳的色彩,优雅,概念艺术,清晰聚焦,数字艺术,超现实主义,4K,虚幻引擎,高度详细,高清,戏剧性照明,Brom,正在 Artstation 上流行。
使用 xformers 的生成仍然很慢。
所有加载到 GPU。… 总进度: 100%|████████████████████████████████████████████████████████████████████████████████████| 20/20 [12:03<00:00, 36.41s/it]

使用 Forge、Flux、Python 3.11 和 xformers 制作的第三张图片。
结果看起来不错,但生成速度很慢。也许我们真的需要 Python3.10,慢速与 Python 版本(xformers)有关。
学习到的经验:
- Python3.11 可能有效,但 Xformers 仍然存在问题。
Python 3.10
让我们再次删除 venv,安装 python3.10,然后创建 venv:
rm -rf venv
sudo apt install python3.10 python3.10-venv python3.10-dev
python3.10 -m venv venv
source venv/bin/activate
pip install --upgrade pip
./webui.sh
安装顺利进行,没有错误。
让我们安装 xformers,首先尝试 cu124 版本,因为我的 nvidia-smi 显示 NVIDIA-SMI 550.107.02 驱动版本:550.107.02 CUDA 版本:12.4。你可以检查哪个 xformers 适合你:
GitHub - facebookresearch/xformers: 可构建和优化的 Transformers 构建块,支持…可构建和优化的 Transformers 构建块,支持…
pip3 install -U xformers --index-url https://download.pytorch.org/whl/cu124
崩溃到 AttributeError:部分初始化的模块 'torchvision' 没有属性 'extension'(很可能是由于循环导入)。也许 Pytorch 的 124 版本太新了,所以,卸载 xformers 并尝试旧版本:
pip uninstall xformers
pip3 install -U xformers --index-url https://download.pytorch.org/whl/cu121
同样,崩溃到 AttributeError:部分初始化的模块 'torchvision' 没有属性 'extension'(很可能是由于循环导入)。看起来 Pytorch 现在太新了,我懒惰,重新删除 venv 并重新创建并安装所需的包:
rm -rf venv
python3.10 -m venv venv
source venv/bin/activate
pip install --upgrade pip
./webui.sh
pytorch 版本:2.3.1+cu121,所以 pip3 install -U xformers — index-url https://download.pytorch.org/whl/cu121 应该可以,但似乎更新太多。
成功安装 nvidia-cudnn-cu12–9.1.0.70 torch-2.4.1+cu121 triton-3.0.0 xformers-0.0.28.post1。
./webui.sh 正常加载后端:
pytorch 版本:2.4.1+cu121 xformers 版本:0.0.28.post1 设置 vram 状态为:NORMAL_VRAM 设备:cuda:0 NVIDIA GeForce GTX 1080 Ti:本地 VAE dtype 偏好:[torch.float32] -> torch.float32 使用 xformers 交叉注意力 使用 xformers 注意力用于 VAE。
所以,使用默认参数进行测试,如前所述(Euler 简单,20 步),同样的提示:
“中世纪的哈莉·奎因和小丑,肖像,顽皮,幻想,中世纪,美丽的面孔,鲜艳的色彩,优雅,概念艺术,清晰聚焦,数字艺术,超现实主义,4K,虚幻引擎,高度详细,高清,戏剧性照明,Brom,正在 Artstation 上流行。”
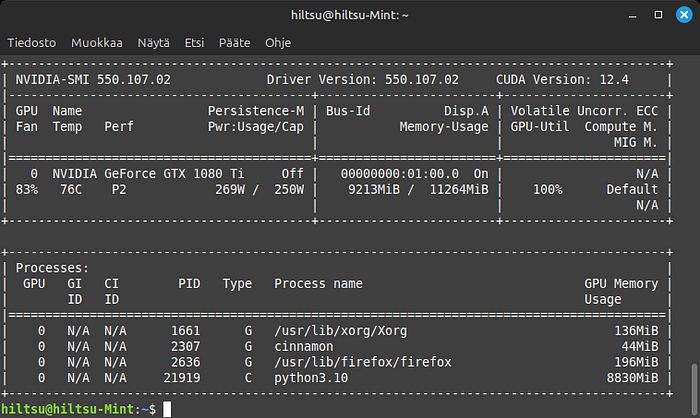
GPU 利用率不是 100%。
仍然很慢,生成时间 12:04。

使用 Python 3.10 和 pytorch 版本:2.4.1+cu121 xformers 版本:0.0.28.post1 制作的第四张图片。
学习到的经验:
- 与 Xformers 一起工作的 Pytorch 版本并没有提高速度。
使用 Euler beta 采样器的 Python3.10 的 Forge
为了好玩,让我们尝试使用 Beta 设置的 Eurler,并将步骤减少到 10。生成时间是否应该是之前 20 步的一半?
是的,生成时间约为一半,05:50,35.03s/it,但结果有点怪异 :)

Flux,Euler beta,10 步。
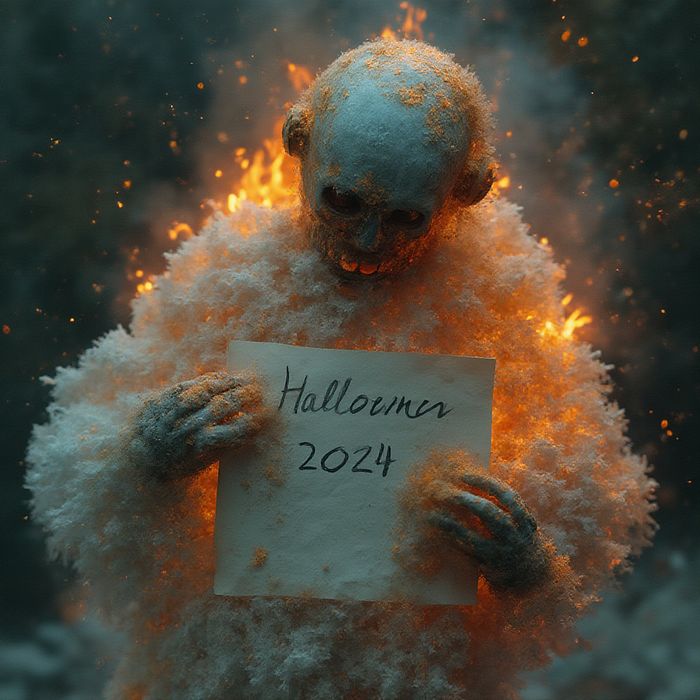
机器人手持写有“2024 万圣节”的纸张。内部是冰球,火焰模式,燃烧的火焰,水从冰中滴落,火焰扭曲成烟雾,空气和地球元素。黄金比例,疯狂的细节,杰作,35mm 摄影,单反相机,柯达胶卷,8K,HDR,鲜艳而生动的色彩,反射。步骤:20,采样器:Euler,调度类型:简单,CFG 比例:1,蒸馏 CFG 比例:1.5,种子:97913728,大小:1024x1024,模型哈希:bea01d51bd,模型:flux1-dev-bnb-nf4-v2,版本: f2.0.1v1.10.1-previous-569-g6dc71b7e。耗时:10 分 42.7 秒。
同样的提示与 flux_1_dev_hyper_8steps_nf4.safetensors(这不应该与 Nvidia 1080 Ti 一起工作,但它工作了)。

机器人手持写有“2024 万圣节”的纸张。内部是冰球,火焰模式,燃烧的火焰,水从冰中滴落,火焰扭曲成烟雾,空气和地球元素。黄金比例,疯狂的细节,杰作,35mm 摄影,单反相机,柯达胶卷,8K,HDR,鲜艳而生动的色彩,反射。步骤:20,采样器:Euler,调度类型:Beta,CFG 比例:1,蒸馏 CFG 比例:7,种子:2365019855,大小:1024x1024,模型哈希:7e8c93b83c,模型:flux_1_dev_hyper_8steps_nf4,Beta 调度 alpha:0.6,Beta 调度 beta:0.6,版本: f2.0.1v1.10.1-previous-569-g6dc71b7e。耗时:10 分 40.5 秒。

机器人(金属生物)笑着,手持芬兰国旗(蓝十字,白色)。在图米奥基尔科(芬兰)屋顶上。黄金比例,疯狂的细节,杰作,35mm 摄影,单反相机,柯达胶卷,8K,HDR,鲜艳而生动的色彩,反射。步骤:10,采样器:Euler,调度类型:Beta,CFG 比例:1,蒸馏 CFG 比例:3.5,种子:3837994734,大小:896x1152,模型哈希:7e8c93b83c,模型:flux_1_dev_hyper_8steps_nf4,Beta 调度 alpha:0.6,Beta 调度 beta:0.6,版本: f2.0.1v1.10.1-previous-569-g6dc71b7e。耗时:6 分 26.7 秒。
使用 Python3.11 的 Automatic1111
让我们将速度与同一台计算机上的 Automatic1111 SDXL 进行比较,使用 xformers:
…
应用注意力优化:xformers… 完成。模型加载时间为 52.7 秒(从磁盘加载权重:1.7 秒,创建模型:0.5 秒,将权重应用于模型:48.4 秒,应用 half():0.1 秒,计算空提示:1.9 秒)。 100%|█████████████████████████████████████████████| 7/7 [00:30<00:00, 4.36s/it] [Tiled VAE]: 输入大小很小,不需要切片。26<00:00, 4.17s/it] 总进度: 100%|█████████████████████████████| 7/7 [00:29<00:00, 4.23s/it] 总进度:100%|█████████████████████████████| 7/7 [00:29<00:00, 4.17s/it]

Automatic1111,步骤:7,采样器:DPM++ SDE,调度类型:Karras,CFG 比例:2,种子:2328055557,大小:1024x1024,模型哈希:4496b36d48,模型:dreamshaperXL_v21TurboDPMSDE,版本:v1.10.1,源标识符:稳定扩散 web UI
生成时间为 0:29 分钟,结果看起来不错。
学习到的经验:
- 适配 torch 等以适应 CUDA 版本 12.4 需要工作,但也许没有理由从默认的 12.1(2.3.1+cu121)更新,因为它以类似的方式工作。
- 不知何故,Automatic1111 比 Forge 更快。
使用 SDXL 模型的 Forge
请记住,如果你在同一台计算机上运行 Forge 和 Automatic1111,你可以在设置中设置路径,或使用软链接,例如 ln -s /opt/stable-diffusion-webui/models/Stable-diffusion/ /opt/forge/stable-diffusion-webui-forge/models/Stable-diffusion/ 等。
使用 Automatic1111 生成的前一张图片的时间为 0:29。让我们看看使用 Forge 和相同的 dreamshaperXL 模型的速度:

中世纪的哈莉·奎因和小丑,肖像,顽皮,幻想,中世纪,美丽的面孔,鲜艳的色彩,优雅,概念艺术,清晰聚焦,数字艺术,超现实主义,4K,虚幻引擎,高度详细,高清,戏剧性照明,Brom,正在 Artstation 上流行。步骤:8,采样器:DPM++ SDE,调度类型:Karras,CFG 比例:1.9,种子:4171555793,大小:896x1152,模型哈希:3d0e279924,模型:dreamshaperXL_v21TurboDPMSDE,版本: f2.0.1v1.10.1-previous-569-g6dc71b7e。
生成时间为 00:53,虽然不如 Automatic1111 快,但也足够快。

机器人手持写有“2024 万圣节”的纸张。内部是冰球,火焰模式,燃烧的火焰,水从冰中滴落,火焰扭曲成烟雾,空气和地球元素。黄金比例,疯狂的细节,杰作,35mm 摄影,单反相机,柯达胶卷,8K,HDR,鲜艳而生动的色彩,反射。步骤:10,采样器:DPM++ SDE,调度类型:Karras,CFG 比例:2,种子:1489079570,大小:1024x1024,模型哈希:7ac04a9474,模型:jibMixRealisticXL_v140CrystalClarity,版本: f2.0.1v1.10.1-previous-569-g6dc71b7e。耗时:2 分 13.4 秒。
使用 Flux dev-fp8 模型的 Forge(适用于 1080 Ti)
经过几次与 CUDA 12.4 及相关 torch 和 xformers 的测试,我无法将 Forge 的生成时间加快到与 Automatic1111 使用相同 SDXL 模型的速度。
对于旧款 NVIDIA 显卡,NF4 Flux 模型是错误的选择。NVIDIA 1080 Ti 不应支持 NF4,但正如你从之前的图片中看到的,我能够生成图片,但速度非常慢。
适合旧 GPU 的正确版本应为 https://huggingface.co/lllyasviel/flux1_dev/blob/main/flux1-dev-fp8.safetensors。
不要启用低位设置中的扩散或任何 NF4 相关设置,保持为自动!
这个例子是使用 flux1-dev-fp8.safetensors(=没有 NF4)生成的,生成时间为 11 分钟。
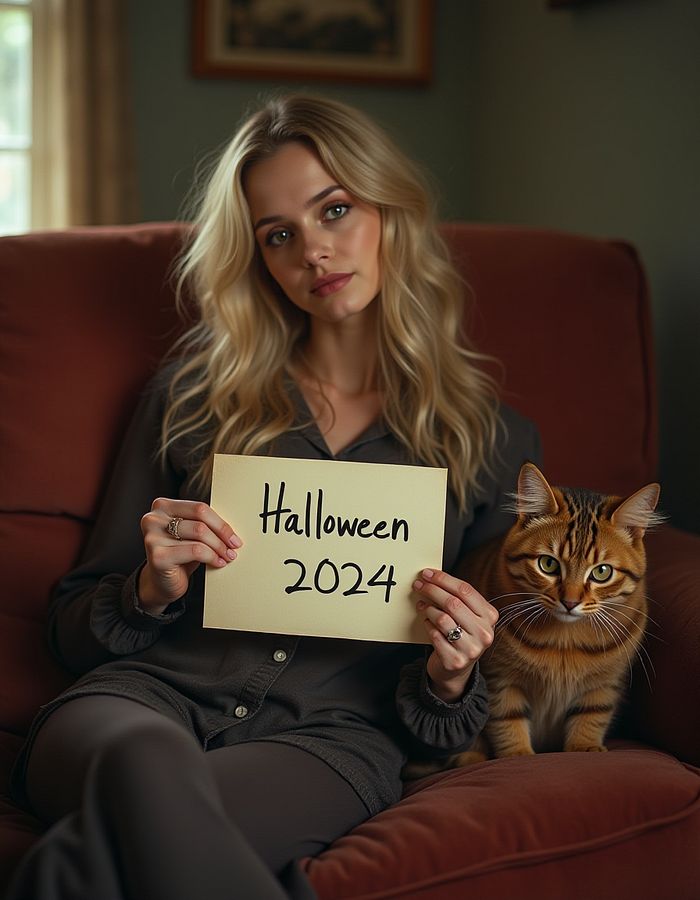
使用 15 步的 flux1-dev-fp8.safetensors,生成时间为 11 分钟。
因此,基于这些测试,你可以在相对较旧的计算机上运行 Forge 和 Flux 模型,但速度显著慢于使用 Automatic1111 和 SDXL 模型。
祝你测试愉快!
推荐阅读:

FluxAI 中文
© 2026. All Rights Reserved