
在Google Colab中训练你自己的Hunyuan视频和Flux LoRA模型!
超过 1 年前
在 Google Colab 中训练自己的 LoRA 模型用于 Hunyuan 视频和 Flux
到 2025 年 1 月,我们已经有了一些很好的图像和视频生成模型。Flux 用于图像生成,Hunyuan Video 用于视频生成。让我们快速了解一下它们的功能。
Flux
Flux 是来自 Black Forest Labs 的开源图像生成模型。
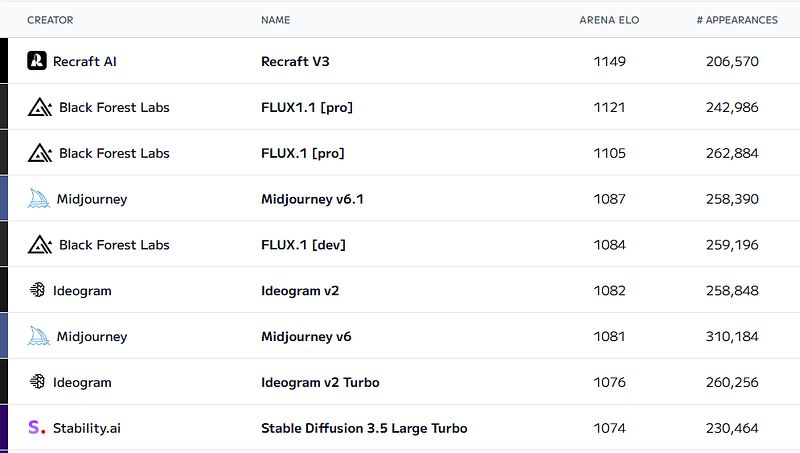
在 文本到图像排行榜 中,Flux 是开源模型中图像生成的 SOTA(最佳目前技术)。
传统流行的图像生成模型 Stable Diffusion 使用 UNET 来生成图像。UNET 是 Stable Diffusion 的核心组件,负责生成噪声 → 进行去噪以生成最终图像。
 来自 维基百科 的 Stable Diffusion 去噪过程
来自 维基百科 的 Stable Diffusion 去噪过程
与传统的 Stable Diffusion 不同,Flux 使用 扩散变换器 架构进行图像生成,就像 Black Forest Labs 博客中提到的那样。
您可以在 Flux 中使用自然语言作为提示。对于许多 SD 模型,您可能需要使用由逗号分隔的单词序列,例如“女人,照片,微笑,正面”。然而,在 Flux 中,您可以使用自然语言,比如“一个微笑着、望向前方的女人的照片。”在 Flux 的推理管道中,这是通过加载两个 CLIP 模型并使用它们的嵌入来实现的。有关 Flux 工作原理的更多信息,请阅读 Black Forest Labs 的官方博客。
如果您尝试在没有任何量化的情况下运行完整的 Flux 模型,您可能需要相当昂贵的硬件。但现在您可以使用 GGUF 格式,可以简单选择最适合您硬件的量化版本。例如,如果您拥有 RTX 3060 12GB GPU,flux1-dev-Q5_K_S.gguf 最适合您。
下图是来自 mimicpc 的 SD 3.5 与 Flux 之间的质量比较:
 来自 mimicpc 的 SD 3.5 和 Flux 比较
来自 mimicpc 的 SD 3.5 和 Flux 比较
Hunyuan Video
Hunyuan Video 是来自 腾讯 的开源视频生成模型。
我在 Hugging Face 或其他地方找不到合适的文本到视频排行榜,所以无法展示。但这是来自 Replicate 的生成示例:
 提示:与水蒸汽机车在山间轨道上并行驶的动态镜头,镜头从车轮移动到蒸汽在雪山上的背景。史诗般的规模,戏剧性的光照,照片般的细节。
提示:与水蒸汽机车在山间轨道上并行驶的动态镜头,镜头从车轮移动到蒸汽在雪山上的背景。史诗般的规模,戏剧性的光照,照片般的细节。
在我看来,Hunyuan Video 是开源文本到视频生成模型中的 SOTA 模型。尽管 Hunyuan Video 尚不支持图像到视频,但有传言称该功能可能将在 2025 年第一季度发布。
像今天许多 SOTA 模型一样,Hunyuan Video 也使用变换器架构,具有其自身的设计。
 来自 Hunyuan Video 的双流到单流设计
来自 Hunyuan Video 的双流到单流设计
具体来说,他们使用 双流到单流 结构进行视频生成。在双流阶段,文本和视频令牌在各自的变换器块中独立处理(每个流)。然后,在单流阶段,它们被串联并输入到后续的变换器块中。这种设计使模型能够学习其适当的调制机制,而不会相互干扰,从而生成更好的视频质量。
由于视频生成变换器利用帧之间的额外信息,Hunyuan Video 使用 3D VAE。3D VAE 在视频长度、空间和通道三个维度上工作。它们的压缩比设置为 4、8 和 16。使用 3D VAE 显著减少了后续扩散变换器模型中的令牌数量。有关其工作原理的更多信息,可以阅读 Hunyuan Video: A Systematic Framework For Large Video Generative Models。
与 Flux 一样,即使您没有足够的 VRAM,您仍然可以运行 Hunyuan Video 模型,这要归功于 GGUF 格式。只需选择最适合您 GPU 的量化版本即可。
Lora
LoRA(大语言模型的低秩适应) 是一种流行的训练技术,可以使用特定数据集对模型进行微调。它通过向模型插入较少的新权重并仅训练这些权重来工作。由于您只训练基础模型中的少量参数,可以更快、更便宜并且更加高效地使用数据集进行微调。
一旦您使用 LoRA 训练了模型,您将拥有一个较小的、从基础模型衍生的适应模型。这个较小的 LoRA 模型可以在推理管道中附加和分离,达到期望的结果。这正是 LoRA 的设计目的。
因为 LoRA 冻结了基础模型的原始权重,并通过插入少量新权重生成期望的结果,因此它提供了灵活性和良好的可扩展性。在训练出一个稳定的基础模型后,您可能更希望拥有几个小的 LoRA 模型,而不是重新训练整个基础模型。
由于其性价比,LoRA 已成为一种非常流行的训练技术。
为 LoRA 训练准备数据集
数据集通常包含与相应文本文件配对的图像,用于描述。
在为 LoRA 模型训练时使用带有标题的数据集,有一些有用的信息。这是一种广泛使用的技术。让我们通过实际训练一个示例 LoRA 模型来看看。
这是一个示例数据集:diffusers/dog-example:

该数据集包含 5 张小狗的图像。这些图像的共同特征是小狗坐着,而不是跑动或玩耍。
我想对小狗本身进行训练,而不是对“坐着的小狗”的概念进行训练。那么我该怎么做呢?
在对数据集中图像进行标注时,一个重要的考虑因素是强调您希望模型清晰学习的特征。如果您希望隔离某个特征,建议对其详细标注。
例如,假设您想为一个佩戴发夹的角色训练一个 LoRA。如果您希望 LoRA 模型生成该角色佩戴和不佩戴发夹的图像,建议包含特意提到发夹的标题。这一原则同样适用于其他特征,例如服装、发型、眼睛颜色等。
由于我不想让 LoRA 过拟合“坐”的概念,所以我应该具体标注小狗的坐姿。
为了比较使用坐姿标题和不使用它们的结果,我准备了两个不同的数据集。
 没有“坐着”的标题
没有“坐着”的标题
 有“坐着”的标题
有“坐着”的标题
它们基本上是相同图像的数据集。我只是在标题中标注了“坐着”和未标注的两个版本。我暂时将小狗命名为“约翰的狗”。由于这个词在标题中反复使用,因此它将成为 LoRA 模型的“触发词”。
在将每个 LoRA 模型训练 1000 步后,以下是使用这些 LoRA 模型生成的示例结果,提示为:“一只约翰的狗正在草地上玩球。”:

左边的图像是使用没有“坐着”关键字的 LoRA 模型生成的,而右边的图像是使用带有“坐着”关键字的 LoRA 模型生成的。
在我看来,右边的图像似乎不太过拟合“坐”的概念。
使用的种子是 77。您可以从这里重新生成结果或进行进一步测试:
如果我能找到一个佩戴发夹、帽子或其他具有鲜明特征的服装的角色的数据集,那将是一个更好的例子。
在 Colab 中训练 LoRA
为了训练适用于 Hunyuan 和 Flux 的 LoRA 模型,我建议查看 ostris/ai-toolkit 和 tdrussell/diffusion-pipe。它们是微调视觉生成模型的不错项目。
为了方便起见,我创建了与 Google Colab 兼容的 Jupyter Notebook。
Colab 是 Google 的 Jupyter Notebook 托管服务,您可以租用一些 Google 的计算资源来运行 Jupyter Notebook。使用 Colab 有几个优点:
- 免费 GPU 运行时,最多支持 16 GB VRAM (T4 GPU)
- 支持在笔记本中填写表单字段,这对不熟悉编码的用户非常有帮助。
 表单字段
表单字段
在我看来,Colab 是向那些对阅读代码不感兴趣的用户展示项目的好方法。
一旦准备好了数据集,就很好能够通过简单地按顺序运行单元格来训练 LoRA 模型,而这可以通过 Jupyter Notebook 实现。
如果您对使用笔记本进行 LoRA 训练感兴趣,请访问:
GitHub — jhj0517/finetuning-notebooks 在 GitHub 上创建帐户为 jhj0517/finetuning-notebooks 的发展做贡献。 github.com
参考
- https://github.com/black-forest-labs/flux
- https://en.wikipedia.org/wiki/Stable_Diffusion
- https://www.mimicpc.com/learn/flux-vs-sd3-5-which-model-is-better
- https://github.com/Tencent/HunyuanVideo
- https://replicate.com/tencent/hunyuan-video/examples
- https://huggingface.co/docs/diffusers/en/training/lora
- https://github.com/tdrussell/diffusion-pipe
- https://github.com/ostris/ai-toolkit
- https://huggingface.co/datasets/diffusers/dog-example?row=4
推荐阅读:





FluxAI 中文
© 2026. All Rights Reserved