
【选择指南】揭秘:如何挑选适合Flux的完美GGUF?
超过 1 年前
Flux.1 Dev/Schnell 是一款强大的 AI 模型,拥有 120 亿个参数,但其 FP16 版本需要占用高达 23GB 的存储空间。要高效运行这个模型,通常需要高端 GPU,比如 NVIDIA RTX 4090(24GB 显存) 或更高级的硬件。然而,大多数用户并没有这样的设备,他们通常使用的是 RTX 4060、4070、4080 或更早的 30 系列 GPU。
那么,如果你的 GPU 无法胜任这个任务,该怎么办呢?通常有两种选择:
- 使用 云计算 来弥补硬件不足。
- 升级 到显存更大的 GPU,比如 RTX 4090。
但还有一种更经济实惠的解决方案:量化。通过降低模型的精度,量化可以显著减少显存需求,而不会对输出质量造成太大影响。这就像压缩图片,虽然文件变小了,但人眼几乎看不出质量下降。
📍 本指南的目的
本指南旨在帮助你根据 GPU 的显存容量,选择最适合的 Flux.1 量化版本。如果你想深入了解量化的技术细节,文末还提供了额外的资源。
🗜️ 什么是量化?
量化 是一种让模型变得更小、更高效的技术。想象一下,把一本 1000 页的书压缩成一份摘要,但仍然保留了所有关键信息——这就是量化的核心思想。它通过减少模型的大小和复杂性,使其能够在资源有限的设备上运行。
🎛️ 什么是 GGUF 格式?
GGUF 是一种专门用于存储量化模型的文件格式。它在存储效率和运行性能上都进行了优化,使得量化模型更容易加载和运行,即使在显存较少的硬件上也能流畅使用。
✔️ 如何选择合适的 GGUF 模型
要选择合适的 Flux.1 GGUF 模型,你需要考虑以下几点:
- 显存容量:你的 GPU 有多少显存?
- 量化级别(Q4、Q5、Q8 等):这决定了模型性能和输出质量之间的权衡。
- 你的具体需求:根据你的硬件和期望的质量,可能需要做出一些妥协。
🎚️ 什么是 GGUF 量化级别?
量化级别 指的是模型精度被降低的程度。例如,将模型从 FP16 压缩到 Q8、Q6 甚至 Q4,可以显著减少其大小和运行所需的显存。不同的量化级别(如 Q2 到 Q8)代表了不同程度的压缩,会影响模型的质量和显存占用。
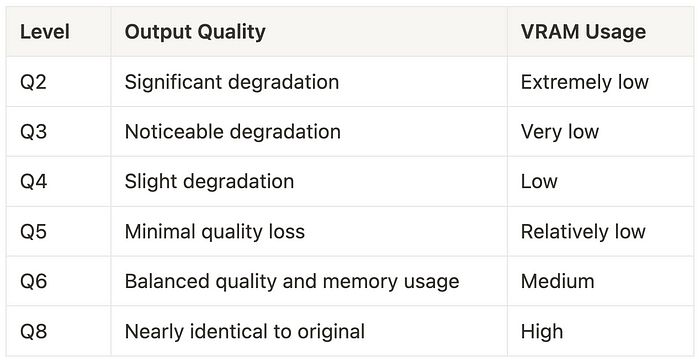
*如果你在 Hugging Face 下载页面上看到 Q2-Q8 量化选项和一个 flux1-dev-F16.gguf 文件,可以将其理解为 FP16 模型封装在 GGUF 格式中。这保留了 FP16 的效率,同时使模型更容易分享并与不同工具兼容。由于它需要与 FP16 相同的 24GB 显存,因此未包含在表格中。
🗒️ 如何估算显存需求
你可以根据模型的文件大小粗略估算所需的最小显存。例如,如果你的 GPU 有 12GB 显存,理论上可以运行 Q5 或 Q6 模型。但请记住,系统本身也需要占用一些显存,因此你可能需要选择更低的量化级别,比如 Q4,以确保稳定运行。建议测试不同版本,找到最适合你设备的配置。
Flux.1 Dev GGUF Q2-Q8 版本列表
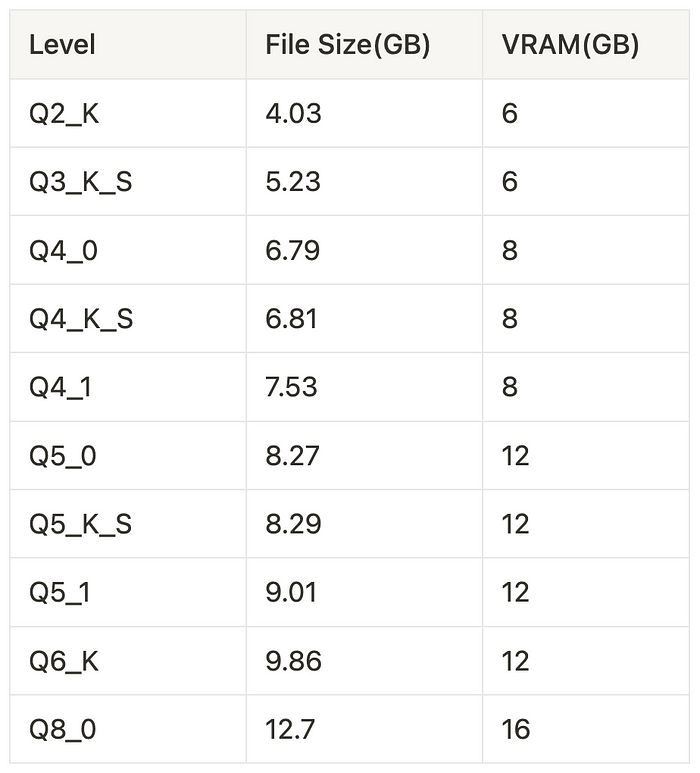
此表格基于 City69 的 Flux.1 Dev GGUF 的版本列表。

NVIDIA 显卡上的显存芯片
📦 使用 City96 的 Flux.1 Dev GGUF
开源的 Flux 社区 有多个贡献者创建了不同的量化模型。本文重点介绍 City96 的 Flux.1 Dev/Schnell GGUF,它支持 ControlNet 和 LoRA。需要注意的是,它不包含 CLIP 或 VAE,因此你需要单独下载这些组件。如果你使用 ComfyUI,还需要相应的 GGUF 工作流。
注意:Flux 需要两个 CLIP 模型——
clip_l和t5xxl。如果你的显存有限,可以考虑使用t5xxl_fp8_e4m3fn.safetensors。
GGUF 模型
CLIP 模型
VAE 模型
ComfyUI 工作流

结论
选择合适的 Flux.1 GGUF 模型主要取决于你的 显存容量。量化 提供了一种有效的方式来优化硬件使用,让你无需购买最昂贵的 GPU 也能运行强大的模型。确保仔细评估你的 GPU 规格和需求,找到最适合的量化版本。
🔗 参考链接
推荐阅读:






FluxAI 中文
© 2026. All Rights Reserved