
《数据科学入门指南:从零到一的进阶之路》
超过 1 年前
生成式人工智能(GenAI)的进展速度快得惊人。它在各种文本驱动的任务中变得越来越成熟,从典型的自然语言处理(NLP)发展到独立的AI代理,能够自主执行高级任务。然而,在图像、音频和视频创作方面,它仍处于起步阶段。虽然这些领域还很新,难以控制,有时甚至有些花哨,但它们每个月都在进步。举个例子,下面的视频展示了视频生成在过去一年中的演变,以著名的“吃意大利面_基准_”为例。
在这篇文章中,我将重点介绍视频生成,并向你展示如何生成包含你自己或真实世界物体的视频——如下面的“GenAI圣诞节”视频所示。本文将回答以下问题:
- 如今的视频生成技术有多好?
- 是否可以生成围绕特定物体的视频?
- 我如何自己创建一个视频?
- 我能期待什么样的质量?
让我们直接开始吧!
GenAI视频生成的类型
通过AI生成视频有多种形式,每种形式都有其独特的能力和挑战。通常,你可以将GenAI视频分为以下三类:
- 包含已知概念和名人的视频
- 基于图像生成的视频,从经过微调的图像生成模型开始
- 基于编辑内容的图像生成视频
让我们逐一详细分析!
包含已知概念和名人的视频
这种类型的视频生成完全依赖于文本提示,使用大型视觉模型(LVM)已经知道的概念来生成内容。这些通常是通用概念(例如:“低角度镜头捕捉到一群粉红色的火烈鸟在郁郁葱葱、宁静的泻湖中优雅地涉水。”——如下所示的Veo 2演示),混合在一起以创建一个与输入提示高度一致的视频。

由Google的Veo 2生成的视频——提示:低角度镜头捕捉到一群粉红色的火烈鸟在郁郁葱葱、宁静的泻湖中优雅地涉水。[…]
然而,一张图片胜过千言万语,而提示词永远不会这么长(即使提示词这么长,视频生成也不会完全遵循)。这使得这种方法几乎不可能创建一致的后续镜头,以适合更长的视频。例如,看看可口可乐2024年完全由AI生成的广告——以及其中卡车的缺乏一致性(它们在每一帧中都变了!)。
学习:使用文本到视频模型几乎不可能创建一致的后续镜头。
刚才提到的限制有一个例外——名人。由于他们在媒体上的广泛存在,LVM通常有足够的训练数据来生成这些名人的图像或视频,遵循文本提示的命令。再加上一些_露骨_的内容,你就有机会走红——如下面The Dor Brothers的音乐视频所示。不过,请注意他们仍然难以保持一致性,正如每帧中衣服的变化所示。
GenAI工具的普及使人们比以往任何时候都更容易创建自己的内容。这很棒,因为它是一种创造力的推动者,但也增加了滥用的可能性。这反过来又引发了重要的伦理和法律问题,特别是关于同意和虚假陈述的问题。如果没有适当的规则,有害或误导性内容可能会充斥数字平台,使我们更难相信我们在网上看到的内容。幸运的是,许多工具(如Runway)都有系统来标记可疑或不适当的内容,帮助控制局面。
学习:由于名人拥有大量的(视觉)数据,他们可以被一致地生成,这理所当然地引发了伦理和法律问题。幸运的是,大多数生成引擎通过标记此类请求来帮助监控滥用行为。
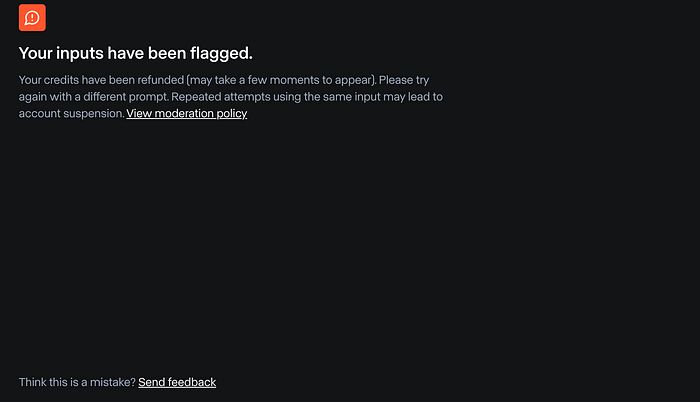
Runway因检测到名人而阻止视频生成。
基于图像生成的视频,从经过微调的图像生成模型开始
生成视频的另一种流行方法是从生成的图像开始,该图像作为视频的第一帧。这一帧可以是完全生成的——如下面的第一个示例所示——或者基于经过轻微修改的真实图像,以提供更好的控制。例如,你可以手动修改图像,或者使用图像到图像模型。一种方法是通过修复,如下面的第二个示例所示。
学习:使用图像作为生成视频中的特定帧提供了更大的控制,帮助你将视频锚定到特定视图。
— 帧可以使用图像生成模型从头创建。
— 你可以使用图像到图像模型来更改现有图像,使其更适合故事情节。

基于生成图像的猫读书视频,使用Flux生成图像,并使用Runway将图像转换为视频。

基于真实图像的猫读书视频,使用Flux进行修复,并使用Runway将图像转换为视频。
其他更复杂的方法包括使用风格迁移模型完全改变照片的风格,或者让模型学习特定概念或人物以生成变体,如DreamBooth所做的那样。然而,这非常难以实现,因为微调并不简单,需要大量的试错才能做好。此外,最终结果总是“尽善尽美”,输出质量在调优过程开始时几乎无法预测。尽管如此,如果做得好,结果看起来非常棒,如下面的“逼真的辛普森一家”视频所示:
基于编辑内容的图像生成视频
最后一种选择——这也是我在本文开头展示的视频中主要使用的方法——是在将图像输入图像到视频生成模型之前手动编辑图像。这些手动编辑的图像随后作为生成视频的起始帧,甚至作为中间帧和最终帧。这种方法提供了显著的控制,因为你只受限于自己的编辑技能和视频生成模型在锚定帧之间的解释自由度。下图展示了我如何使用Sora在两个连续的锚定帧之间创建过渡。
学习:大多数视频生成工具(Runway、Sora等)允许你指定起始、中间和/或结束帧,从而在视频生成过程中提供很大的控制力。

从起始帧到结束帧的过渡,使用Flux 1.1 Schnell生成两个背景,并使用Sora进行视频生成。请注意,Sora在视频的第二帧中生成了机器人的俯视图——这是一个“幸运的意外”,因为它非常合适。
最棒的是,编辑的质量甚至不需要很高,只要视频生成模型理解你想要做什么。下面的示例展示了初始编辑——简单地将机器人复制粘贴到生成的背景场景中——以及这是如何转化为机器人在森林中行走的视频的。
学习:低质量的编辑仍然可以生成高质量的视频。

基于(糟糕的)编辑图像的AI生成视频,其中机器人被简单地粘贴到场景中,使用Runway生成的视频。
由于生成的视频由自编辑的图像锚定,因此控制视频的流程变得容易得多,从而确保后续镜头更好地结合在一起。在下一节中,我将详细介绍如何做到这一点。
学习:手动编辑特定帧以锚定生成的视频,可以让你创建一致的后续镜头。
制作你自己的视频!
好了,长话短说,现在你如何_真正_开始制作视频呢?
接下来的三个部分将逐步解释我是如何制作本文开头视频中的大部分镜头的。简而言之,它们几乎总是遵循相同的方法:
- 步骤1:通过图像生成生成场景
- 步骤2:对你的场景进行编辑——即使是糟糕的编辑也可以!
- 步骤3:将你的图像转换为生成的视频
让我们动手吧!
步骤1:通过图像生成生成场景
首先,让我们生成特定场景的背景。在我创建的音乐视频中,提到了越来越聪明的代理,所以我决定教室背景会很好。为了生成这个场景,我使用了Flux 1.1 Schnell。个人而言,我发现Black Forest Labs的Flux模型比OpenAI的DALL-E3、Midjourney的模型或Stability AI的Stable Diffusion模型更令人满意。
学习:在撰写本文时,Black Forest Labs的Flux模型提供了最好的文本到图像和修复结果。

使用Flux 1.1 Schnell生成的空教室图像。
步骤2:对你的场景进行编辑——即使是糟糕的编辑也可以!
接下来,我想在场景中加入一个玩具机器人——视频的主题。为此,我拍摄了机器人的照片。为了更容易去除背景,我使用了绿幕,尽管这不是必需的。如今,像Daniel Gatis的rembg或Meta的Segment Anything Model (SAM)这样的AI模型非常擅长做这件事。如果你不想担心这些模型的本地设置,你也可以使用在线解决方案,如remove.bg。

真实世界玩具机器人的图像捕捉。
一旦你去除了主体的背景——并可选地添加一些其他组件,如哑铃——你可以将它们粘贴到原始场景中。编辑得越好,生成的视频质量越高。我似乎没有成功解决光线设置的问题。尽管如此,令人惊讶的是,即使从非常糟糕的编辑图像开始,视频生成也可以非常好。对于编辑,我建议使用Canva,这是一个易于使用的在线工具,学习曲线非常小。
学习:Canva非常适合编辑图像。

拍摄的玩具机器人手持哑铃的编辑图像。
步骤3:将你的图像转换为生成的视频
一旦你有了锚定帧,你可以使用选择的视频生成模型和精心设计的提示将它们转换为视频。为此,我尝试了Runway的视频生成模型和OpenAI的Sora(遗憾的是,还没有访问Google的Veo 2的权限)。在我的实验中,Runway通常给出了更好的结果。有趣的是,Runway Gen-3 Alpha _Turbo_的成功率最高,而不是它的老大哥Gen-3 Alpha。这很好,因为它更便宜,而且视频生成模型的生成积分非常昂贵且稀缺。根据我在网上看到的视频,Google的Veo 2似乎是生成能力的又一次大飞跃。希望它很快就能普遍可用!
学习:Runway的Gen-3 Alpha Turbo的成功率高于Runway的其他模型——Gen-2和Gen-3 Alpha——以及OpenAI的Sora。
— 所有平台上的生成积分都非常昂贵且稀缺。你花的钱得不到太多回报,尤其是在生成过程中高度依赖“运气”的情况下。

基于编辑起始帧的AI生成视频,使用Runway生成。
不幸的是,生成视频仍然更多的是失败而不是成功。虽然在场景中移动摄像机相当简单,但要求视频主体进行特定运动仍然_非常_困难。像“举起右手”这样的指令几乎是不可能的——所以不要想尝试指导_如何_举起主体的右手。为了说明这一点,下面是前一节中讨论的从起始帧到结束帧过渡的失败生成。对于这个生成,指令是放大一个雪地道路,上面有一个机器人在行走。更多滑稽的视频生成失败,请参见下一节;“注意!期待失败……”。
学习:生成视频更多的是失败而不是成功。特别是定向运动仍然具有挑战性,几乎是不可能的。

从起始帧到结束帧视频过渡的失败生成,使用Runway生成。
重复……
一旦你得到了满意的结果,你可以重复这个过程以获得连续的镜头,使它们更好地结合在一起。这可以通过多种方式完成,比如创建一个新的起始帧(见下面的第一个示例),或者通过使用上一代生成的最后一帧继续视频生成,但使用不同的提示来改变主体的行为(见下面的第二个示例)。

基于新创建的起始帧的合适下一个镜头的示例。

基于上一代生成的最后一帧的合适下一个镜头的示例。这种方法严重依赖视频生成提示来改变场景。
注意!期待失败……
如前所述,生成视频非常困难,所以请保持低期望。你想生成一个特定的镜头或运动吗?没机会。你想生成一个好看的_任何东西_的镜头,但你不在乎具体是什么吗?是的,那可能行得通!生成的结果很好,但你想稍微改变一下吗?又没机会了……
为了让你对这个过程有一点感觉,这里是我在创建视频过程中生成的一些_最佳_失败的汇编。

失败的视频生成,均从编辑的起始帧开始。左上:“穿着欧盟旗帜的驯鹿出现[…]”。右上:“机器人在管弦乐队中演奏[…]”。左下:“机器人帮助辅导孩子[…]”。右下:“机器人将坐在它后面的沙发上[…]”。使用Sora或Runway生成的视频。
从普通视频到音乐视频——将你的故事变成歌曲
蛋糕上的樱桃是一个完全由AI生成的歌曲,以补充视频中描绘的故事。当然,这实际上是蛋糕的_基础_,因为音乐是在视频之前生成的,但这并不是重点。重点是……音乐生成变得多么棒!
本文开头音乐视频中使用的歌曲是使用Suno创建的,这是迄今为止给我带来最大“哇!”因素的AI应用程序。生成实际上相当不错的音乐的轻松和速度令人惊叹。为了说明这一点,音乐视频在五分钟内生成——这包括模型处理的时间!
学习:Suno太棒了!
我理想的音乐生成工作流程如下:
- 使用ChatGPT(简单的4o就可以,o1并没有增加太多)进行故事头脑风暴,并提取好的部分。
- 将好的部分和想法汇聚成完整的歌词,通过向ChatGPT提供反馈和手动编辑来完成。
- 使用Suno(v4)生成歌曲,并尝试不同的风格。如果某些词听起来不对,可以重写(例如,将“GenAI”写成“Gen-AI”以避免发音为“genaj”)。
- 在Suno(v4)中重新制作歌曲。这提高了歌曲的质量和范围,几乎总是比原始版本更好。
所有学习的总结
总结一下,以下是我在制作自己的音乐视频和撰写本文时学到的所有经验:
- 使用文本到视频模型几乎不可能创建一致的后续镜头。
- 由于名人拥有大量的(视觉)数据,他们可以被一致地生成,这理所当然地引发了伦理和法律问题。幸运的是,大多数生成引擎通过标记此类请求来帮助监控滥用行为。
- 使用图像作为生成视频中的特定帧提供了更大的控制,帮助你将视频锚定到特定视图。
- 帧可以使用图像生成模型从头创建。
- 你可以使用图像到图像模型来更改现有图像,使其更适合故事情节。
- 大多数视频生成工具(Runway、Sora等)允许你指定起始、中间和/或结束帧,从而在视频生成过程中提供很大的控制力。
- 低质量的编辑仍然可以生成高质量的视频。
- 手动编辑特定帧以锚定生成的视频,可以让你创建一致的后续镜头。
- 在撰写本文时,Black Forest Labs的Flux模型提供了最好的文本到图像和修复结果。
- Canva非常适合编辑图像。
- Runway的Gen-3 Alpha Turbo的成功率高于Runway的其他模型——Gen-2和Gen-3 Alpha——以及OpenAI的Sora。
- 所有平台上的生成积分都非常昂贵且稀缺。你花的钱得不到太多回报,尤其是在生成过程中高度依赖“运气”的情况下。
- 生成视频更多的是失败而不是成功。特别是定向运动仍然具有挑战性,几乎是不可能的。
- Suno太棒了!
推荐阅读:





FluxAI 中文
© 2026. All Rights Reserved