
使用Flux Gym进行Flux LoRA训练与ComfyUI图像创作:完整教程大揭秘!
超过 1 年前

使用文本-图像扩散模型生成的图像
Flux LoRA 训练与通过 ComfyUI 在 Google Colab 上创建图像:完整指南
扩散模型是一类生成模型,通过反复精炼噪声学习生成数据样本。受热力学扩散的启发,这些模型从纯噪声分布开始,逐步使用学习到的变换进行去噪,有效地捕捉复杂的数据分布。
它们在生成高质量图像、音频甚至分子结构方面表现出色。与传统的生成模型(如 GANs 和 VAEs)相比,扩散模型在模式覆盖、训练稳定性和灵活性方面更具优势,成为生成 AI 应用的强大工具。在本文中,我们将探讨一种称为 LoRA(低秩适应) 的微调技术,以微调这些扩散模型。
低秩适应(LoRA)是一种旨在高效微调扩散模型的强大技术。通过引入可训练的低秩矩阵来冻结预训练模型的权重,LoRA 显著减少了训练所需的计算资源和时间,同时保持或甚至提高了性能。
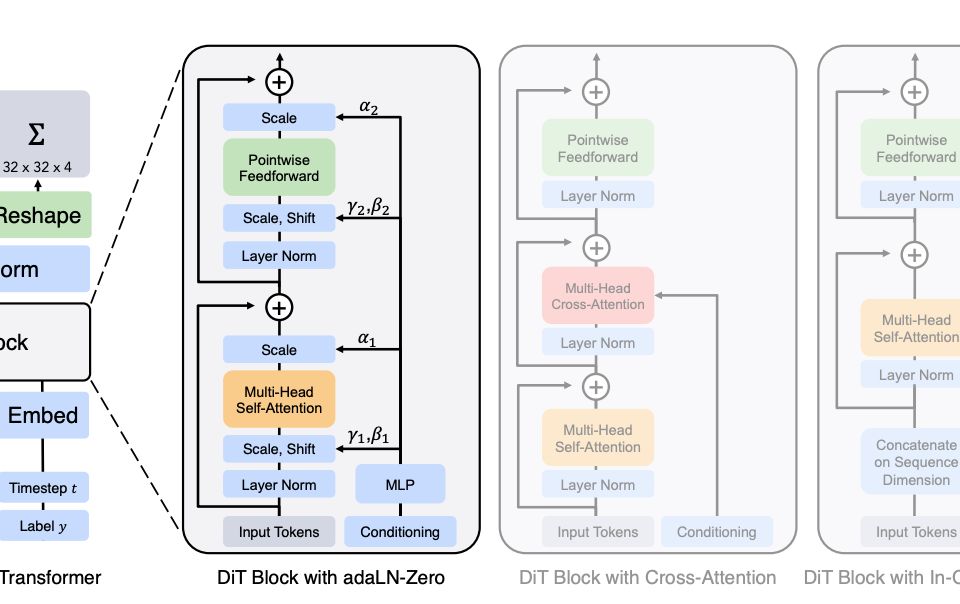
Flux 是一个用户友好的框架,简化了 LoRA 的实现,使得微调重量级/稠密扩散模型变得更加容易。
在这篇文章中,我们将探索如何利用 FluxGym 和 ComfyUI 等工具进行 LoRA 的训练,并使用简单的提示生成个性化图像。
在 Colab 上设置 Flux Gym 进行 LoRA 训练:
要开始微调 LoRA,我们将使用一个叫做 FluxGym 的框架。这个框架允许我们通过简单的图形用户界面(GUI)来训练 LoRA,在这里我们可以输入一些图像及其对应的标题。使用 FluxGym 训练 LoRA 的过程变得非常流畅。
设置 Flux Gym 的步骤:
在
/content/fluxgym-Colab/目录中克隆 Flux Gym 仓库及 sd-scripts 仓库:!git clone https://github.com/TheLocalLab/fluxgym-Colab.git %cd /content/fluxgym-Colab/ !git clone -b sd3 https://github.com/kohya-ss/sd-scripts安装必要的依赖项:
%cd /content/fluxgym-Colab/sd-scripts/ !pip install -r requirements.txt %cd /content/fluxgym-Colab/ !pip install -r requirements.txt !pip install --pre torch==2.4 torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121安装依赖项后,下载所需的模型。要使用 Flux Gym 进行 LoRA 训练并通过 ComfyUI 生成图像,需要多个预训练模型文件,包括 UNet 结构、文本编码器和变分自编码器(VAEs)的组件。使用以下命令直接从 Hugging Face 获取这些文件:
!wget -O /content/fluxgym-Colab/models/unet/flux1-dev-fp8.safetensors https://huggingface.co/Kijai/flux-fp8/resolve/main/flux1-dev-fp8.safetensors !wget -O /content/fluxgym-Colab/models/clip/clip_l.safetensors https://huggingface.co/comfyanonymous/flux_text_encoders/resolve/main/clip_l.safetensors?download=true !wget -O /content/fluxgym-Colab/models/clip/t5xxl_fp8.safetensors https://huggingface.co/comfyanonymous/flux_text_encoders/resolve/main/t5xxl_fp8_e4m3fn.safetensors?download=true !wget -O /content/fluxgym-Colab/models/vae/ae.sft https://huggingface.co/cocktailpeanut/xulf-dev/resolve/main/ae.sft?download=true
文件解释:
**flux1-dev-fp8.safetensors**(UNet 模型):这是扩散模型的核心。它通过学习反向扩散步骤来处理去噪过程。该模型的其他精度版本,如 FP16 或 FP32,也可以从同一个 Hugging Face 仓库 下载。**clip_l.safetensors**(CLIP 文本编码器):基于 CLIP 的文本编码器,用于将文本提示与图像对齐以进行条件生成。该模型学习文本和图像的共享嵌入空间,使其能够理解语义关系,并提高基于提示的图像合成的准确性。**t5xxl_fp8.safetensors**(T5 文本编码器):基于 T5 架构的额外文本编码器,已量化为 FP8 以提高计算效率。该模型的其他精度版本也可在 Hugging Face 仓库 中找到。**ae.sft**(变分自编码器): VAE 对图像进行编码和解码,减少其维度,同时保留质量。
运行 Flux Gym:
现在,运行
app.py文件以启动 Gradio 界面:!python app.py
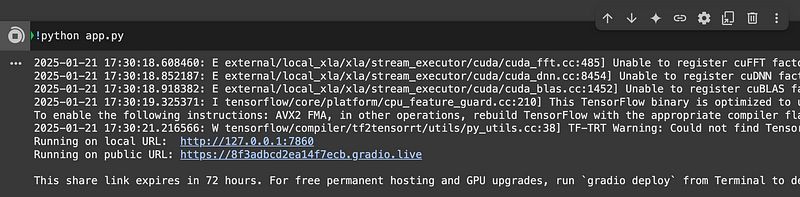
公共 URL,用于运行 Gradio 界面
Flux Gym 界面主要分为三个部分:
部分 1:LoRA 信息
在这里,我们可以定义参数,例如要为我们的 LoRA 模型指定的名称、触发词、显存、每幅图像的重复训练、最大训练轮数等。我们观察到该版本的 FluxGym 在 16GB 显存 下效果最佳。在尝试时,我们发现 12GB 和 20GB 显存 的训练选项存在一些问题。
部分 2:数据集
在这里,我们输入我们的训练图像,一旦插入训练图像,我们为这些图像提供标题(不要忘记在每个标题中添加触发词)。
部分 3:训练
在这里,我们可以检查训练脚本和训练配置。一旦确认,我们可以点击“开始训练”按钮以启动训练。
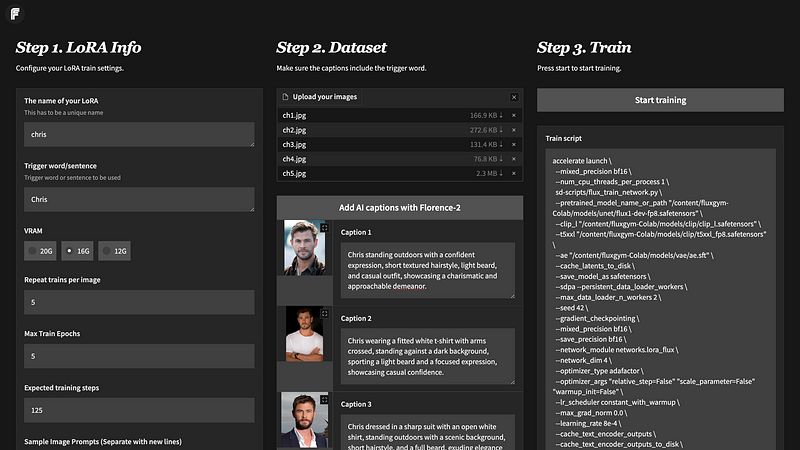
Flux Gym Gradio 界面
模型训练完成后,请确保使用以下代码片段下载模型文件:
from google.colab import files filename = '/content/fluxgym-Colab/outputs/<你的-LoRA-名称>.safetensors' files.download(filename)
使用 ComfyUI 生成图像:
要通过提示使用 ComfyUI 生成图像,请按照以下步骤操作:
在 Colab 中克隆 ComfyUI 仓库,并安装所有所需的依赖项。
!git clone https://github.com/comfyanonymous/ComfyUI ComfyUI %cd ComfyUI !pip install xformers!=0.0.18 -r requirements.txt --extra-index-url https://download.pytorch.org/whl/cu121 --extra-index-url https://download.pytorch.org/whl/cu118 --extra-index-url https://download.pytorch.org/whl/cu117要运行 UNET 模型,我们需要下载一个自定义节点以在 ComfyUI 上运行。为此,我们可以在
/content/ComfyUI/custom_nodes目录中克隆该仓库。然后安装所有依赖项。%cd custom_nodes !git clone https://github.com/city96/ComfyUI-GGUF.git !ls %cd ../.. !python3 -m pip install -r ./ComfyUI/custom_nodes/ComfyUI-GGUF/requirements.txt现在,我们可以将为训练下载的模型移动到
/content/ComfyUI/models目录下的相应子目录,或使用以下命令直接下载模型:# 直接从 Hugging Face 的原始链接下载所需模型 !wget -c https://huggingface.co/city96/FLUX.1-dev-gguf/resolve/main/flux1-dev-Q8_0.gguf -P ./models/unet/ !wget -c https://huggingface.co/openai/clip-vit-large-patch14/resolve/main/model.safetensors -P ./models/clip/ !wget -c https://huggingface.co/comfyanonymous/flux_text_encoders/resolve/main/t5xxl_fp16.safetensors -P ./models/clip/ !wget -c https://huggingface.co/black-forest-labs/FLUX.1-dev/resolve/main/vae/diffusion_pytorch_model.safetensors -P ./models/vae/同时,手动将下载的 LoRA 模型上传到
/content/ComfyUI/models/lora目录中。现在,为了访问 ComfyUI 界面,我们需要创建一个公共链接。这可以通过 cloudflared/localtunnel/colab iframe 来完成。但今天我们使用 Ngrok 创建公共 URL。
让我们设置一个可通过 Ngrok 访问的 ComfyUI 服务器。首先从 这里 创建 Ngrok 的身份验证令牌,并使用
ngrok.set_auth_token()设置 Ngrok 身份验证令牌。然后创建一个后台线程来监视端口8188,并在检测到服务器后启动 Ngrok 隧道,打印公共 URL 以便远程访问。最后,使用subprocess.run()启动 ComfyUI,使用--dont-print-server标志。此设置便捷地初始化 ComfyUI,并使其可通过互联网访问,几乎没有任何努力。!pip install pyngrok import subprocess import threading import time import socket from pyngrok import ngrok ngrok.set_auth_token(NGROK_AUTH_TOKEN) def iframe_thread(port): while True: time.sleep(0.5) sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) result = sock.connect_ex(('127.0.0.1', port)) if result == 0: break sock.close() print(" ComfyUI 加载完成,正在尝试启动 Ngrok... ") public_url = ngrok.connect(port) print(f"访问 URL: {public_url}") threading.Thread(target=iframe_thread, daemon=True, args=(8188,)).start() subprocess.run(["python", "main.py", "--dont-print-server"])现在点击生成的公共链接,并在主页上点击“访问网站”按钮。这将把你重定向到 ComfyUI 界面。点击左上角的“工作流”按钮,将需要从 这里 下载的 ComfyUI 工作流文件上传。
加载工作流后,请确保在 Unet Loader、DualClipLoader、Load LoRA 和 Load VAE 节点中选择下载的模型,点击右箭头按钮进行验证。
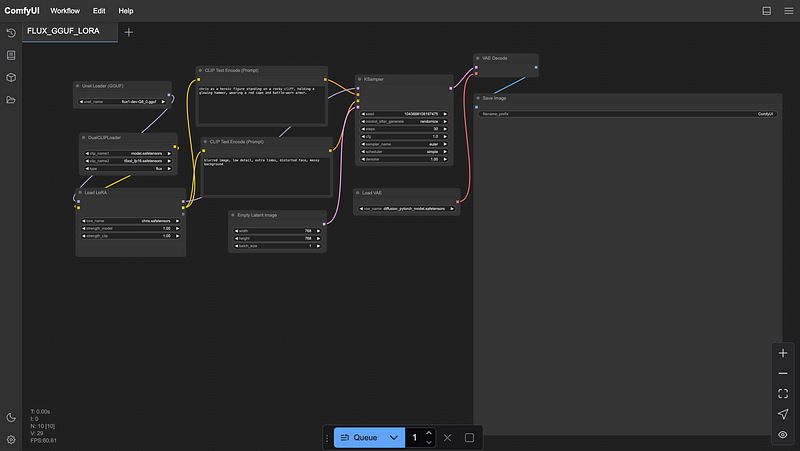
ComfyUI 配置完成
- 现在给出一个提示** (必须添加触发词),根据我们的需求更改空潜在图像的宽度和高度,然后点击 **队列 按钮。可以在第二个 CLIP 文本编码节点中给出负提示,明确指示模型要避免什么。一旦图像生成,你可以在“保存图像”节点中查看图像。
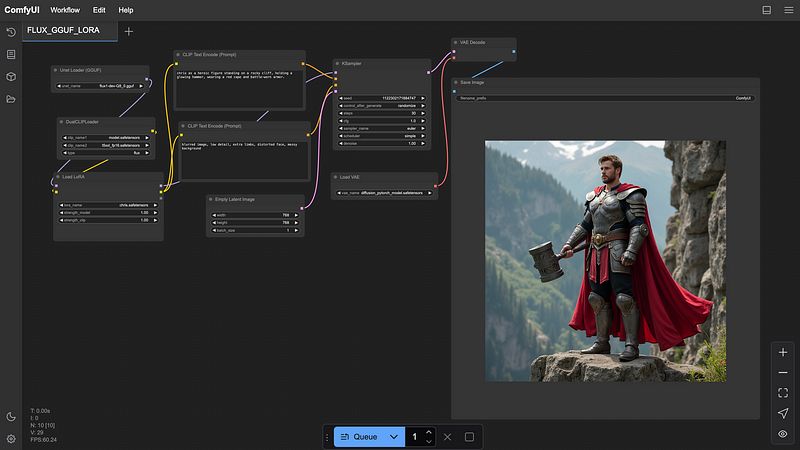
ComfyUI 工作流与生成的图像
参数如步数、cfg、采样器名称等可以进行实验,以便根据我们的喜好生成图像。
以下是一些生成的图像:

由 LoRA 生成的克里斯·海姆斯沃斯图像
这些图像展示了在五张克里斯·海姆斯沃斯的图像上训练 Flux LoRA 的结果,优化了八个周期,每张图像进行了五次重复。生成的视觉效果富有创意,展示了不同的主题,融合了奇幻和科幻的美学,强调了模型如何在各种富有想象力的场景中推断和风格化主题特征。
结论:
通过本指南,您现在拥有使用 Flux Gym 训练 Flux LoRA 的工具和知识,并通过 ComfyUI 在 Colab 上创建惊艳的图像。结合微调过的 LoRA 的强大能力和 ComfyUI 的灵活性,无论是为个人项目还是专业工作,您都可以将您的创造性构想变为现实。可能性是无穷无尽的——开始实验,让您的想象力引领方向吧!
撰文者 — Thejas P Rao (https://www.linkedin.com/in/thejasprao/)
推荐阅读:


FluxAI 中文
© 2026. All Rights Reserved