
🎬 用一句话,让视频秒变大片!Meta新功能揭秘(4/5)
超过 1 年前
引言
Movie Gen Edit 是一个生成式 AI 模型,它能够根据输入的视频和编辑指令输出一个经过编辑的视频。这个模型是从 Movie Video Gen 模型衍生而来的,后者能够根据文本提示生成视频和图像。
对于 Meta AI 研究团队来说,开发这个模型一定感觉像是一项永无止境的任务。在了解了它的开发过程后,他们所经历的试错过程至少可以说是痛苦的。
无论如何,让我们聚焦于他们是如何将这个模型变为现实的。
问题
想想训练这个模型需要什么样的数据?一个数据样本应该包含一个视频、一条编辑指令以及编辑后的视频。这种数据并不容易获取,或者需要花费大量时间才能收集到成千上万条。
如果没有所需的数据,我们如何能开发出一个能够根据输入的视频和编辑指令来编辑视频的模型呢?
解决方案
利用预训练的文本到视频模型 (Movie Gen Video),并通过三个不同的阶段进行训练,每个阶段都有独特的目标。

Movie Gen Edit 的三阶段训练过程
第一阶段:单帧编辑
让模型能够根据输入的单帧视频(图像)和编辑指令生成编辑后的图像。
第二阶段:多帧编辑
利用“第一阶段”开发的模型,逐帧生成视频及其编辑版本的数据。利用这些数据,重新训练第一阶段模型,使其能够根据输入的视频和编辑指令生成一个简短的编辑视频。
第三阶段:视频编辑
利用“第二阶段”开发的模型,生成视频及其编辑版本的数据。使用这些数据重新训练模型,将编辑后的视频和反向编辑指令作为输入,原始视频作为模型最终需要预测的目标。
你注意到了吗?我们利用能够收集到的数据(图像及其编辑版本),开发出我们想要的数据(视频及其编辑版本),然后利用这些数据来训练我们想要的模型。
让我们逐个阶段来看,并通过 FTI 架构来理解这个过程,就像我们在之前的博客中所做的那样。
所有代码示例均使用 Claude Sonnet 3.5 进行了增强
第一阶段:单帧编辑
特征管道
他们为此所需的数据集是图像编辑数据集。每个数据样本包含三元组 (c_img, c_instruct, x_img),其中:
c_img:输入图像(视为单帧视频)c_instruct:编辑指令文本x_img:目标编辑后的输出图像
这个特征存储将存储所有输入图像的向量形状、编辑指令文本以及编辑后输出图像的向量形状。
我忘记提到另一个重要的点。模型除了输出编辑图像的目标外,还受到视频生成目标的约束。当目标是视频生成时,c_img 只是一个空白视频。但为什么呢?
他们希望保留模型生成视频的能力,保持时间一致性,因为单帧视频是训练过程的一部分。
所以我们的特征存储有一堆三元组 (c_img, c_instruct, x_img),其中 c_img 在视频生成的情况下是一个空白视频。
训练管道
为了适应这个目标,对实际的 Movie Video Gen 模型进行了以下架构修改。主要是他们向模型添加了两个额外的条件输入(与文本嵌入一起)。
- 条件输入 2:一个以视频为输入的条件输入,并与噪声视频潜在空间混合(高斯噪声 + 目标视频潜在空间 (目标视频潜在空间是 TAE 编码器的输出,其输入是目标视频))
- 条件输入 3:任务嵌入向量,它与文本嵌入混合,并与 Transformer 块混合。为什么?为了让模型能够执行各种编辑任务,即我们通过任务 ID 提供编辑任务的类型。它可能看起来像这样。
视觉表示更容易理解一个概念。这是修改后的整体模型架构的样子。
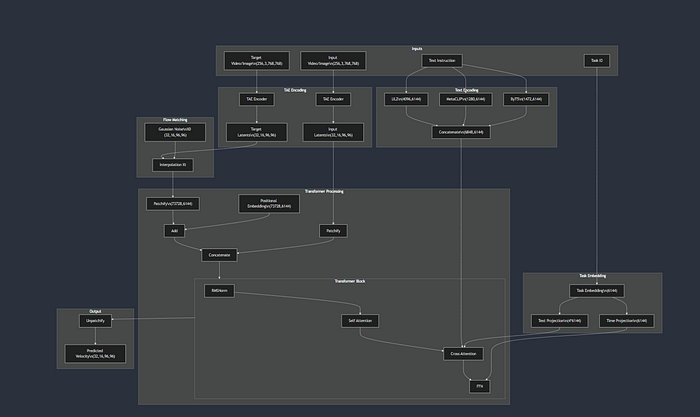
**[图片链接](https://mermaid.live/view#pako:eNqVVm1vmzAQ_ivIH6Ztoh04BEI- TErbbKrUdtGaVtWWfXDASVjBRmC2ZlX_-- 5MCARotKEg7PNzz74szs4zCWTIyZisYvk72LBMGfOzhTDgyYvlOmPpxrgUaaHyUohPhPPvC6Llxn0UcvnhMmFrvliIt3TomgPTc0f4vluQH7WeYtmao- JcD_5Hkz9pPfiAN7nKikBFUrTY80fNnT8alxf7JS7ChWgFhDxTgYFXpHoWifUBYxFTWL-7ouidY_mu6dqOc- hZEEcpgK65YudXlzNE2nRk9SCXWzUE5Nl2PtQox6M9KIzUODn5iMaNN5oePqjbsClFwJQNZOd6xAW8yOmOnFEPZ4dKG9ixHMkSZHKaLHlYZVVPOllSPFl2EehNNzjEoG3UqcVpJn_a1U7MYMLL3cWsv
yIBw3Zh4lvAXvy2ey1Ca1kVfk9EgSJlM0NZn2l4hi3G6u86y9TI8s60YqEwI87UapFmi9EJfbXjbeFe489CXEPaCm7Zo- _g7DBwVaN9y_aKAn2nK8L44qkkp8JF2f4BS5ZirYgFEcG3rSzpqQUY6t95kVeR4xYdygANx6sIzXPYuE4lmqw8eBBE9g240H1YkYylyb0A6Xakd2OGMiX8ks4Rlmqp5hbQUcHGx5n-7im- nQVltMpzfwaF_rpTIv22Mm8wjdZfFhk7ymWHpdVijaaZmHCEtqjWBhiGUxCcN2KuyagTZdPjjC9EFAW8dJE4H8aFHTNA6PRmXWo77EnsUyeGxlV8sOzOATRlnZzvtrqC6aLMEov17f3sCwo5kzWLzl8cqYKCzz9v2gQ0XMeSbz_AhotRJYvZ9uOivaBR1_zso0lB_QqIG6xrpp2WVM49uZ6RztO_LWEdkrpYce9FX4l0LBedG4D0RVwnflqF0Rv3iMxZLxMAoUD417Dl5Ganv04GgHVd5ipQE9Bta9j8QkgEtYFMJfj2cUL4ja8ATqbgzDkGVQGgvxAjhWKHm7FQEZw7XPTZLJYr0h4xWLc5gVaQjVehExCDWpICkT36RsTsn4mTyRMfWGp65lub7r-K5vDz3XJFsytql16nmOPRwOvIFv-f6LSf5oApD7FtzndEQd33Ms9-Uvb9qpYA)****(点击此处放大和移动)**
如果你将上面的图片翻译成一个粗略的 Python 脚本,它可能看起来像这样。
class MovieGenEdit:
def __init__(self):
# 从预训练的 Movie Gen Video 模型初始化
self.transformer = MovieGenVideoTransformer(params=30B)
self.tae = TemporalAutoEncoder()
# 文本编码器
self.ul2 = UL2Encoder()
self.metaclip = LongPromptMetaCLIP()
self.byt5 = ByT5Encoder()
# 添加新的编辑组件
self.add_editing_components()
def add_editing_components(self):
"""编辑的架构修改"""
# 1. 添加输入视频条件
self.patch_embedder.in_channels *= 2 # 为连接增加通道数
# 2. 将新权重初始化为零
self.patch_embedder.weight.data[:, old_channels:, ...] = 0
# 3. 添加可学习的任务嵌入
self.task_embeddings = nn.Embedding(num_tasks, embed_dim=6144)
# 4. 任务投影层
self.task_to_text = nn.Linear(6144, 4 * 6144) # 用于文本条件
self.task_to_time = nn.Linear(6144, 6144) # 用于时间步
def stage_one_training():
config = {
'steps': 30000,
'batch_ratios': {
'image_edit': 5,
'video_gen': 1
},
'learning_rate': 1e-4,
'batch_size': 32
}
model = MovieGenEdit()
optimizer = AdamW(model.parameters(), lr=config['learning_rate'])
for step in range(config['steps']):
# 决定批次类型
is_image_edit = random.random() < (5/6) # 5:1 比例
if is_image_edit:
loss = train_image_edit_batch(model, config)
else:
loss = train_video_gen_batch(model, config)
optimizer.zero_grad()
loss.backward()
optimizer.step()
def train_image_edit_batch(model, config):
"""单批次图像编辑训练"""
# 1. 获取图像编辑数据批次
batch = {
'input_image': shape(32, 3, 768, 768), # [批次, RGB, 高, 宽]
'instruction': ["添加一顶帽子", ...], # 编辑指令
'target_image': shape(32, 3, 768, 768), # 编辑后的图像
'task_id': [0, ...] # 编辑操作类型
}
# 2. 将图像编码到潜在空间
input_latents = model.tae.encode(batch['input_image']) # (32, 16, 96, 96)
target_latents = model.tae.encode(batch['target_image']) # (32, 16, 96, 96)
# 3. 从所有编码器获取文本嵌入
text_embeddings = encode_text_multi(batch['instruction'])
# UL2: (4096, 6144)
# MetaCLIP: (1280, 6144)
# ByT5: (1472, 6144)
# 4. 获取任务嵌入
task_emb = model.task_embeddings(batch['task_id']) # (32, 6144)
# 投影任务嵌入
text_cond = model.task_to_text(task_emb) # 用于文本条件
time_cond = model.task_to_time(task_emb) # 用于时间步
# 5. 流匹配过程
X0 = torch.randn_like(target_latents) # 高斯噪声
t = torch.rand(batch_size, 1) # 随机时间步 [0,1]
# 在噪声和目标之间插值
Xt = t * target_latents + (1-t) * X0
# 真实速度
Vt_truth = target_latents - X0
# 6. 准备 Transformer 输入
# 将 Xt 分块
patches = model.patchify(Xt) # (32, 73728, 6144)
# 添加位置嵌入
pos_emb = get_factorized_pos_embeddings(
temporal=32, # TAE 压缩帧
height=48, # 96/2 从分块
width=48, # 96/2 从分块
dim=6144
)
# 连接输入潜在空间以进行条件处理
input_patches = model.patchify(input_latents)
transformer_input = torch.cat([patches, input_patches], dim=-1)
transformer_input = transformer_input + pos_emb
# 7. 通过 Transformer
for block in model.transformer_blocks:
# RMS 归一化
x = block.rms_norm(transformer_input)
# 自注意力
q, k, v = block.qkv(x)
# 分割头: (32, 73728, 48, 128)
x = block.self_attention(q, k, v)
# 与文本 + 任务条件的交叉注意力
text_cond = torch.cat([text_embeddings, text_cond], dim=1)
x = block.cross_attention(x, text_cond)
# FFN
x = block.ffn(x)
# 添加时间嵌入,条件为任务
time_emb = block.time_mlp(t) + time_cond
x = x + time_emb
# 8. 获取预测速度
predicted_velocity = model.unpatchify(x) # (32, 16, 96, 96)
# 9. 计算损失
loss = F.mse_loss(predicted_velocity, Vt_truth)
return loss
def train_video_gen_batch(model, config):
"""常规视频生成训练以保持能力"""
# 类似于 MovieGenVideo 训练
# 但以空白视频作为输入条件
batch = {
'text': ["一只狗在奔跑", ...],
'video': shape(32, 256, 3, 768, 768)
}
# 创建空白输入条件
input_video = torch.zeros_like(batch['video'])
# 其余训练类似于图像编辑
# 但使用视频生成任务 ID
...
return loss比较 Mermaid 图和上面的脚本,以更好地理解脚本(提示:只需关注 train_image_edit_batch)。以下是您需要理解的重要细节。
- 条件输入和主输入
该模型的条件输入主要是视频、文本和任务 ID。主输入是目标视频。
2. 多任务训练:
训练在图像编辑样本(5/6 的批次)和文本到视频生成样本(1/6 的批次)之间交替进行。为什么文本到视频生成样本较少?因为模型已经能够生成视频,这节省了计算效率。
推理管道
现在我们的推理管道将根据输入的图像、文本指令和任务 ID 生成一个编辑后的图像。请注意,任务 ID 不是我们手动输入的,而是模型根据文本指令学习和确定的。
第二阶段:多帧编辑
特征管道
我们向该模型提供两种相同结构的数据样本,以训练其完成两个目标
- 动画帧编辑任务:给定一个视频和一条编辑指令作为输入,模型应该能够生成一个编辑后的视频。这是多帧编辑,与我们第一阶段执行的单帧编辑不同。为什么?第一阶段模型在输入超过一帧的视频时会产生模糊的编辑视频。
- 生成式指令引导的视频分割:给定一个视频和一条指令,模型标记(着色/分割)特定对象。这个任务得到了解决。为什么?动画帧编辑任务缺乏自然运动。
class StageIIDataPipeline:
def __init__(self):
self.edit_model = StageIModelCheckpoint()
self.dino = DINOModel() # 用于分割
self.sam = SAMModel() # 分割任何模型
self.llama = LLaMa3() # 用于指令生成
def get_training_batch(self, batch_size):
"""根据 3:1:1 的比例获取批次"""
ratio = random.random()
if ratio < 0.6:
# 3/5 概率 - 动画帧编辑
return self.get_animated_frame_batch(batch_size)
elif ratio < 0.8:
# 1/5 概率 - 视频分割
return self.get_segmentation_batch(batch_size)
else:
# 1/5 概率 - 视频生成
return self.get_video_gen_batch(batch_size)
def get_animated_frame_batch(self, batch_size):
"""创建动画帧编辑数据"""
batch = {
'videos': [],
'edited_sequences': [],
'instructions': [],
'task_ids': []
}
for _ in range(batch_size):
# 1. 获取视频和字幕
video = load_video() # shape(256, 3, 768, 768)
caption = video.caption
# 2. 使用 LLaMa3 生成编辑指令
edit_instruction = self.llama.generate_instruction(caption)
# 3. 随机采样一帧
frame_idx = random.randint(0, len(video)-1)
frame = video[frame_idx] # shape(3, 768, 768)
# 4. 使用第一阶段模型编辑单帧
edited_frame = self.edit_model(
frame,
edit_instruction
)
# 5. 创建动画序列
input_sequence = []
target_sequence = []
# 序列中的帧数
n_frames = random.choice([128, 192, 256])
for i in range(n_frames):
# 随机仿射变换
transform = self.get_random_affine_transform()
# 应用于原始帧和编辑帧
input_frame = transform(frame)
target_frame = transform(edited_frame)
input_sequence.append(input_frame)
target_sequence.append(target_frame)
# 将帧堆叠为张量
input_video = torch.stack(input_sequence)
target_video = torch.stack(target_sequence)
batch['videos'].append(input_video)
batch['edited_sequences'].append(target_video)
batch['instructions'].append(edit_instruction)
batch['task_ids'].append(ANIMATE_EDIT_TASK_ID)
推荐阅读:



FluxAI 中文
© 2026. All Rights Reserved