
【深度解析】Transformer如何颠覆序列建模?揭秘背后的奥秘!(下篇)🤖
超过 1 年前
🌟 为什么选择自注意力机制?
序列转换任务中不同层类型的比较 🤔
自注意力机制通过解决循环层和卷积层的关键限制,彻底改变了序列转换任务。它被广泛认为是处理变长符号序列映射的黄金标准:
(x1,…,xn)→(z1,…,zn),其中 xi, zi ∈Rd。
本次比较从以下几个方面评估不同层类型:
- 🚀 每层的计算复杂度
- ⚡ 并行化能力
- 🔗 长距离依赖的路径长度
🔑 自注意力机制的优势
自注意力机制结合了二次计算复杂度、无与伦比的并行化能力以及捕捉依赖关系的恒定路径长度,解决了RNN和CNN的局限性。这使得它成为序列转换任务的理想选择,尤其是在需要局部精度和全局上下文的应用中。
💡 关键点: 自注意力机制在计算效率和表示能力之间取得了平衡。其适应各种上下文的灵活性以及随序列长度扩展的能力,确保了它在多样化应用中的主导地位。
🚀计算复杂度
自注意力机制的计算复杂度为 O(n^2⋅d),在序列长度 n 小于嵌入维度 d 的情况下,它可以优于循环层的 (O(n⋅d^2))。这种效率在机器翻译等任务中尤为有利,因为分词技术(如词片段或字节对编码)通过将输入序列表示为子词单元来减少其长度。
然而,当序列长度显著增加时,自注意力机制的二次复杂度会成为瓶颈。为了解决这个问题,研究人员开发了各种优化技术,确保自注意力机制在处理极大数据集或长序列时仍然可行。
🛠 长序列的优化
在处理非常长的序列时(如整本书、视频或基因组数据),完全全局的自注意力机制可能会变得计算上不可行。可以采用以下几种策略来局部化或减少注意力计算,同时保持性能:
窗口化注意力:
- 注意力限制在每个标记周围的固定大小邻域(窗口)内。
- 将计算复杂度降低到 O(n⋅r),其中 r 是窗口大小,显著提高了长序列的效率。
应用场景:
- 文档摘要: 专注于特定部分或段落,确保模型捕捉有意义的局部上下文,而无需处理整个文档。
- 视频理解: 仅关注相邻帧或视频片段,避免对所有帧进行全局计算。
稀疏注意力:
- 根据预定义的模式(如跨步、块状或随机)选择性地关注一部分标记。
- 减少不必要的计算,同时保持捕捉局部和远距离依赖的能力。
应用场景:
- 基因组学: 通过专注于生物学相关位置(如基因或调控区域)来处理数百万个元素的序列。
低秩近似:
- 像Linformer和Performer这样的技术近似注意力矩阵,将复杂度降低到线性时间 O(n)。
- 这些方法使自注意力机制能够高效扩展,而不会牺牲太多准确性。
应用场景:
- 大规模语言模型: 在极长文本语料库上训练像GPT或BERT这样的模型。
分层注意力机制:
- 在多个粒度级别(如单词、句子、段落)上聚合信息。
- 将全局上下文与细粒度的局部细节结合,适用于需要多尺度推理的任务。
📈 实际案例
文档摘要:
自注意力机制可以在局部窗口内操作,例如专注于句子或段落,从而有效地总结关键点,而不是全局关注文档中的每个标记。
视频理解:
在动作识别等任务中,受限的自注意力机制仅处理视频的特定片段,例如围绕重要动作的几帧,而不是分析整个视频序列。
基因组学:
在处理跨越数百万个碱基的基因组序列时,窗口化或稀疏注意力机制专注于生物学显著区域,如基因或调控元件,从而在保持准确性的同时降低计算成本。
💡 提示: 窗口化或稀疏注意力机制在序列长度可能达到数百万个元素的领域(如基因组学、气候建模或天体物理学)中特别有价值。
🔍 进一步分析
为了更好地理解自注意力机制的计算优势,可以比较不同层类型的计算成本:
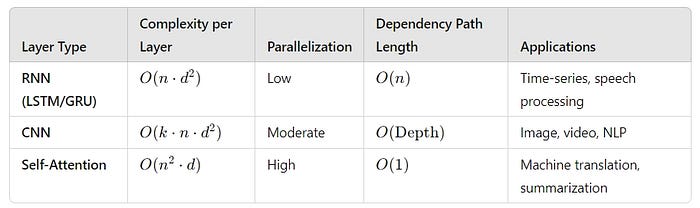
自注意力机制在路径长度为O(1)和高并行化方面表现出色,非常适合翻译和摘要任务。RNN和CNN适用于时间序列和图像任务,但复杂度较高。
🔑 关键洞察
虽然自注意力机制的二次复杂度在长序列中可能是一个问题,但像Linformer、Performer和稀疏注意力这样的先进技术将其复杂度降低到线性时间。这些优化确保自注意力机制在处理最大数据集时仍然实用且有效。
此外,自注意力机制的并行化能力——通过GPU和TPU等框架实现——使其成为现代机器学习管道的明确选择。
💬 讨论点
- 局部化 vs. 全局注意力: 局部化(如窗口化)和全局注意力之间的权衡是什么?例如,虽然窗口化注意力降低了计算成本,但它可能会错过语言建模或情感分析等任务中关键的全局依赖。
- 全局上下文中的稀疏注意力: 稀疏注意力模式在需要整体理解的任务中可能会遇到困难。混合方法如何平衡效率与捕捉全局上下文之间的权衡?
🔧 探索工具
Hugging Face Transformers:
- 提供各种注意力机制的预训练模型,包括BERT和GPT。
- 非常适合在文本数据集上进行微调任务的实验。
Fairseq(Facebook AI Research 序列到序列工具包):
- 高性能工具,用于训练带有自注意力机制的序列模型。
- 专为机器翻译和摘要等任务设计。
PyTorch Lightning:
- 轻量级框架,支持可扩展的训练,内置对基于注意力架构的支持。
- 简化了不同注意力机制和优化的实验。
💡 专业建议: 在需要效率和全面理解序列依赖的任务中,将稀疏注意力和全局注意力结合在混合模型中。
⚡ 5. 并行化能力
循环神经网络(RNN)及其变体(如LSTM和GRU)由于其顺序性质而面临固有的限制。这些模型需要O(n)操作,每个步骤都依赖于前一个步骤的输出。这种严格的顺序依赖使得RNN难以高效并行化,尤其是在处理大数据集或长序列时。因此,它们难以扩展,并且需要大量的时间和计算资源进行训练,使其不太适合高吞吐量任务或需要实时性能的应用。
相比之下,自注意力机制——Transformer模型的核心——打破了这一固有限制。自注意力机制通过允许每个标记同时关注所有其他标记,而不是按顺序逐个处理它们。这导致每个注意力头的复杂度为O(1),与序列长度无关,使模型能够并行处理所有标记。通过这种大规模并行化,Transformer能够有效扩展,充分利用现代硬件加速器(如GPU和TPU)的优势,这些加速器针对并行执行进行了优化。
通过消除顺序瓶颈,自注意力机制显著提高了模型的速度和可扩展性,尤其是在处理长距离依赖或大数据集时。这种能力是BERT、GPT和T5等模型成功的关键因素,这些模型依赖Transformer来高效捕捉数据中的复杂模式。
能够并行执行计算,而不依赖于逐步处理,显著加速了基于Transformer模型的训练和推理时间。例如,机器翻译、文本摘要和问答等任务极大地受益于这种效率。因此,Transformer能够处理更大的输入,更快地处理它们,并最终提供比循环模型更好的结果。
💻 硬件优势
自注意力机制非常适合现代并行化硬件环境。通过消除标记之间的依赖关系,它允许模型充分利用硬件加速器(如GPU和TPU)的全部潜力。这些设备擅长同时执行许多操作,而自注意力机制通过实现快速处理和高效内存使用来利用这种架构。对于计算密集型任务(如训练GPT-3、BERT和T5等大规模模型),自注意力机制的并行执行能力提供了相对于循环架构的明显优势。
在GPU或TPU上执行时,自注意力机制的训练时间比基于RNN的模型快得多,后者依赖于无法有效并行化的顺序操作。此外,注意力机制的并行性减少了处理序列所需的总时间,从而显著加快了模型训练。这种能力不仅使Transformer更高效,而且更具可扩展性,使其能够在相同时间内处理更大的数据集并执行更复杂的操作。
此外,向量化操作(如SIMD,单指令多数据)在GPU和TPU上的使用有助于加速矩阵乘法和注意力分数的计算。这些优化使计算更快,并更有效地利用可用资源,进一步增强了自注意力模型的性能。这种硬件友好的设计是Transformer在深度学习中成为主导架构的关键原因之一,尤其是在自然语言处理(NLP)任务中。
🧠 类比
想象自注意力机制就像一个高效的独立工作团队,每个成员能够同时处理任务的不同部分。每个成员都可以与团队中的任何其他成员互动,并行交换信息,而无需等待其他人完成他们的部分。这种结构使团队能够比单个成员更快地完成任务。相比之下,循环层更像是一个必须完成一个任务才能继续下一个任务的单个成员,导致整体性能较慢。
正如一个团队通过分工和并行处理任务可以胜过单个成员,自注意力机制通过同时处理多个标记及其依赖关系胜过循环层。通过并行处理所有标记,自注意力机制消除了循环模型固有的瓶颈,并提高了速度和效率。这种并行性使Transformer在需要同时处理大量数据的任务中表现出色,如语言翻译、文本生成和复杂推理任务。
从顺序处理到并行化的根本转变是Transformer在广泛应用中超越基于RNN的模型的主要原因之一,尤其是在NLP领域,标记之间的长距离依赖对于捕捉句子或段落的完整意义至关重要。
🔧 优化建议: 为了充分利用硬件上的自注意力机制,可以考虑使用混合精度训练。这种技术涉及在某些操作中使用低精度算术(如float16),同时仍保持足够的模型准确性。混合精度训练在支持低精度计算的GPU和TPU上特别有效。通过使用混合精度,可以显著加速训练和推理,使模型能够在更短的时间内处理更多数据。这种方法还减少了内存消耗,使训练时能够使用更大的批次大小和更长的序列。
使用混合精度可以在不损害模型最终性能的情况下实现显著的加速,使其成为大规模训练任务(如GPT-3或BERT所需的训练任务)的必备技术。此外,这种优化在处理极大模型或在多个设备上并行训练时特别有益。
💡 下一步:
- 探索多头注意力,以更深入地了解Transformer如何在更细粒度上处理并行化。多头注意力允许模型同时关注输入序列的不同方面,每个注意力头关注序列的不同部分。这增加了模型学习数据中多样化模式和关系的能力,同时仍保持并行化操作的能力。
- 进行性能基准测试,比较Transformer与传统顺序模型(如LSTM或GRU)的速度和效率。例如,在机器翻译或文本摘要等任务中,使用Transformer时,您将看到处理时间和模型性能的显著优势。Transformer受益于其并行性,这大大减少了训练时间并提高了整体效率,尤其是在处理长序列或大规模文本语料库时。
此外,在实时应用(如实时翻译或连续数据处理)中评估Transformer模型,可以揭示其在处理大量数据时提供低延迟结果的能力。并发处理标记的能力使Transformer在这种环境中优于顺序模型,其中时间敏感的处理至关重要。
通过拥抱并行化和硬件优化,自注意力模型(如Transformer)提供了一种强大的解决方案,解决了顺序处理的局限性。这些模型在速度和可扩展性方面表现出色,使其能够应对需要高性能和高效利用计算资源的广泛任务。自注意力机制的灵活性和强大功能使其成为现代深度学习中的必备工具,在训练和实时推理场景中提供了相对于传统循环架构的显著优势。
🔗 路径长度与长距离依赖
路径长度是指信号在到达网络其他部分之前需要传播的层数或步骤数。这一因素显著影响模型捕捉长距离依赖的能力,这对于语言建模、机器翻译和文档理解等任务至关重要。
自注意力机制
自注意力机制允许输入序列中所有标记之间的直接连接,路径长度为O(1)。这意味着任何标记都可以直接关注所有其他标记,使其在捕捉数据中的长距离依赖方面表现出色。没有由于顺序步骤导致的延迟,模型可以从一开始就学习全局模式。
循环层
在循环神经网络(RNN)中,路径长度随O(n)扩展,这意味着信号必须通过nnn层才能连接远距离的标记。这使得在学习长序列中的依赖关系时变得困难,因为信号在传播过程中会被稀释或丢失,这种现象被称为梯度消失。
卷积层
卷积层在处理长距离依赖时也存在困难。对于连续核,路径长度扩展为O(n/k),其中_k_是核大小。对于扩张卷积,路径长度对数扩展,O(logk(n)),这允许稀疏的长距离连接。然而,需要多层才能连接远距离标记,这使得它们在处理长距离依赖时不如自注意力机制高效。
关键洞察
自注意力机制中较短的路径长度允许梯度在网络中更快地流动,使得捕捉标记之间的依赖关系变得更容易,无论它们的位置如何。这使得模型能够比路径长度较长的模型(如循环层和卷积层)更有效地学习全局模式。这一特性在需要理解完整上下文的任务中特别有用,如自然语言处理,其中理解单词或短语之间的关系(无论它们的位置如何)至关重要。
🔍 可解释性作为额外优势
自注意力机制的一个突出特点是其固有的可解释性。传统神经网络,尤其是循环神经网络和卷积神经网络,通常被认为是“黑盒”,因为很难理解它们如何得出特定的预测。然而,自注意力机制通过注意力分布提供了有价值的洞察,揭示了模型在每个步骤中关注的内容。
我们观察到的:
- 注意力头的专业化:自注意力网络通常表现出不同的注意力头,这些头专注于各种任务,如语法识别、语义关系或长距离依赖。例如,在句子“The cat sat on the mat”中,一个注意力头可能专注于主语-动词一致性等语法关系,而另一个注意力头可能专注于语义关系,如将“cat”与“mat”连接起来。
- 注意力可视化:通过可视化注意力权重或注意力图,我们可以理解模型如何在序列上分配注意力。这有助于调试模型并通过根据观察到的注意力模式进行调整来提高其准确性。
应用场景:
- 理解错误:如果您的模型始终无法理解某些模式,您可以检查注意力权重,看看它是否关注了输入序列的错误部分。
- 改进微调:可视化注意力图可以突出显示需要微调的领域,帮助您优化模型的特定部分以应对某些任务。
💡 进一步探索的问题
让我们更深入地探讨一些可能塑造自注意力模型未来的开放性问题:
为什么较短的路径长度有助于更好地学习长距离依赖?
- 较短的路径长度有助于梯度更有效地流动,因为它们在传播过程中减少的可能性较小。这支持更好地学习长距离依赖,因为模型可以更清晰地“看到”整个序列。
在自注意力机制中限制感受野如何影响准确性和效率?
- 限制感受野(例如使用局部注意力)可以提高效率,尤其是在处理长序列时。然而,如果错过了关键的长距离依赖,可能会导致准确性下降。这种权衡取决于任务和序列长度。
不同架构在计算复杂度和序列长度之间存在哪些权衡?
- 虽然自注意力机制在处理变长序列时表现出色,但在处理非常长的序列时可能会变得计算昂贵。循环层和卷积层在处理低维度的长序列时更高效,但它们在处理长距离依赖和并行化方面存在困难。
可分离卷积能否与自注意力机制竞争?
- 可分离卷积(如深度可分离卷积)在捕捉局部模式时降低了计算成本,同时保持了良好的性能。然而,它们仍然面临长距离依赖的挑战,并且缺乏像自注意力机制那样同时关注所有标记的能力。
注意力分布的洞察如何指导模型改进或任务特定的微调?
- 注意力分布可以通过突出显示模型忽略或过度关注的标记或输入部分,为任务特定的微调提供信息。通过调整模型以更有效地关注重要元素,可以提高准确性和效率。
🎯 关键要点
- 效率:自注意力层在平衡速度和准确性方面优于循环层和卷积层,尤其是在处理较短序列的任务中。
- 可扩展性:自注意力机制的并行化能力使其成为大规模序列转换任务的首选架构,因为它能更好地扩展以适应GPU和TPU等硬件。
- 灵活性:虽然自注意力机制是处理广泛任务的强大工具,但未来的工作可能会集中在提高其在极长序列中的效率,并增强其可解释性,从而更深入地了解模型的行为。
🌟 利用自注意力机制的专业建议
1. 从预训练模型开始:
- 预训练的Transformer模型(如BERT、GPT、T5)具有高度优化的自注意力层。这些模型随时可用,并且可以通过最少的努力针对特定任务进行微调。
2. 针对硬件进行优化:
- 利用混合精度训练和批次优化,以充分利用您的GPU和TPU。这将减少内存使用并加速计算,而不会牺牲准确性。
3. 尝试局部注意力:
- 对于内存密集型任务,可以考虑将注意力机制限制在局部窗口内,或使用稀疏注意力机制。这可以在处理非常大的输入时减少计算负担。
4. 分析注意力图:
- 可视化注意力权重或注意力图可以帮助您调试模型并理解其决策过程。它还可以为模型改进或任务特定的微调提供有价值的洞察。
📚 库与代码示例
以下是一些用于在Python中实现自注意力机制的有用库:
1. Hugging Face Transformers
Hugging Face提供了广泛的预训练模型,包括BERT、GPT和T5等带有自注意力机制的模型。您可以用最少的代码在自定义数据集上微调这些模型。
from transformers import BertModel, BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') model = BertModel.from_pretrained('bert-base-uncased') inputs = tokenizer("Hello, world!", return_tensors="pt") outputs = model
FluxAI 中文
© 2026. All Rights Reserved