
简要探讨视频生成模型的下一个趋势:扩散变换器
将近 2 年前
在添加变压器组件之前,扩散模型是视频生成的主要架构。
扩散模型是一类生成模型,通过模拟逐渐添加噪声和随后的去噪过程来创建数据。最初,这些模型是为图像生成等任务引入的,它们从一份数据样本(例如图像)开始,逐步在多个步骤中添加高斯噪声,直到其与纯噪声无法区分。在反向过程中,模型学习逐步去除噪声,逐步重建原始数据。这种方法使得扩散模型能够通过有效捕捉数据的潜在分布来生成高质量、逼真的输出。
然后,我们得到了潜在扩散模型
潜在扩散模型是传统扩散模型的高级变体,它在压缩的潜在空间中操作,而不是直接在高维数据(如图像或视频)上。通过首先使用自编码器等技术将输入数据编码为低维表示,这些模型在保留重要特征和结构的同时减少了计算复杂性。扩散过程随后在这个潜在空间中进行,噪声逐渐添加并通过学习的去噪过程被去除。
扩散与潜在扩散的区别
区别在于,潜在扩散在低维潜在空间中执行扩散过程,使用像变分自编码器(VAE)这样的编码器,而不是在原始的高维空间中。
这个潜在空间只是数据的更紧凑的维度,专注于捕捉其重要特征并提高效率。
U-Net在扩散模型中的作用
正向扩散过程逐渐向图像添加噪声,然后使用U-Net从给定的图像中去除噪声。在每个反向扩散步骤中,它接收每个带噪声的图像及其时间步,然后逐步去除噪声,直到得到干净的图像。
这是一个非常简化的U-Net可视化,主要基于卷积神经网络。
扩散变压器的出现
在正常扩散模型中发生的与U-Net相同的过程,现在发生在扩散变压器中,取代了U-Net。之所以表现得比U-Net方法更好,主要原因是变压器在捕捉全局上下文方面非常出色,因为它具有自注意力机制,这意味着它对数据的需求较高,但如果提供足够的数据,它的能力可以超越U-Net的基础架构。
U-Net(左侧)现在被变压器块(右侧)替代,形成了扩散变压器。
U-Net与扩散变压器的比较
在某些情况下,U-Net更好,如果数据量较少,这将减少过拟合的可能性,因为U-Net是一种更简单、参数更少的架构。此外,如果您更专注于局部特征时,U-Net也是更好的选择。
变压器则正好相反,因此如果您有更大的数据,并希望捕捉更多的全局上下文而不是局部特征,那么在扩散过程中使用变压器而不是U-Net作为基础架构是更好的选择。
潜在扩散模型与扩散变压器之间的相似性和差异
潜在扩散模型试图将数据压缩到低维潜在空间,通常使用VAE编码器,目的是捕捉最重要的细节。变压器则利用其自注意力机制来捕捉最重要的细节。
一个关键的区别是,潜在扩散模型按顺序执行扩散过程,而变压器则并行执行扩散过程,使其更快。此外,潜在扩散模型需要先将数据转换为潜在维度,而变压器则不需要这样做。
Latte的出现
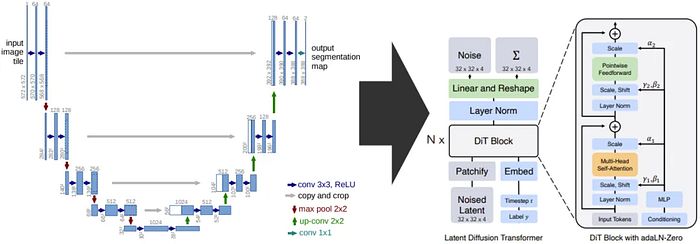
Latte首先使用预训练的变分自编码器将输入视频编码为潜在空间中的特征,然后从这些编码特征中提取标记。
之后,应用一系列变压器块来编码这些标记。由于我们处理的是视频,可以想象我们正在处理大量的标记,具体来说是时空标记。这只是一个花哨的说法,表示包含图像空间(图像中的物体或场景)信息和每个输入图像的时间步(时间)的标记。正如我们之前讨论的,这些标记就是输入到Latte中的变压器块的内容。
图来自官方Latte研究论文《Latte: Latent Diffusion Transformer for Video Generation》。
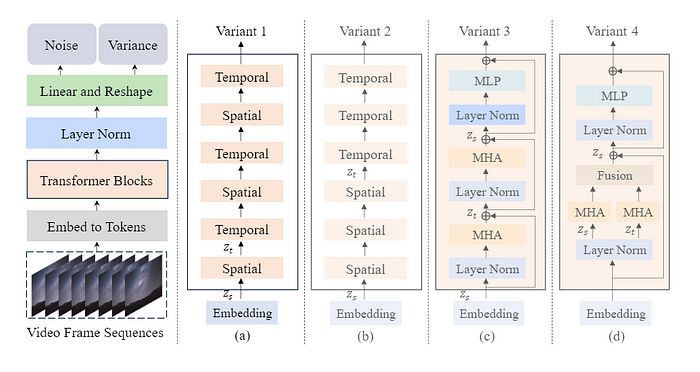
制作Latte的人提出了4种不同的变压器块变体,并进行了测试以查看哪种结构能提供最佳结果。在深入了解这些块之前,让我们先看看整体结构是什么样的。
图来自官方Latte研究论文《Latte: Latent Diffusion Transformer for Video Generation》。
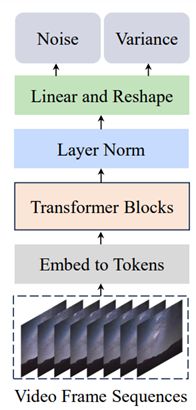
这是Latte的一般结构,视频帧序列被嵌入到标记中(使用我们之前提到的变分自编码器,这是借鉴自稳定扩散1.4),然后传递给变压器块(这里有4种不同的变体)。之后,变压器块的输出传递给层归一化等。
这里的主要焦点是中间的变压器块,他们有4种不同的变体,主要关注高效捕捉输入视频中的时空信息。
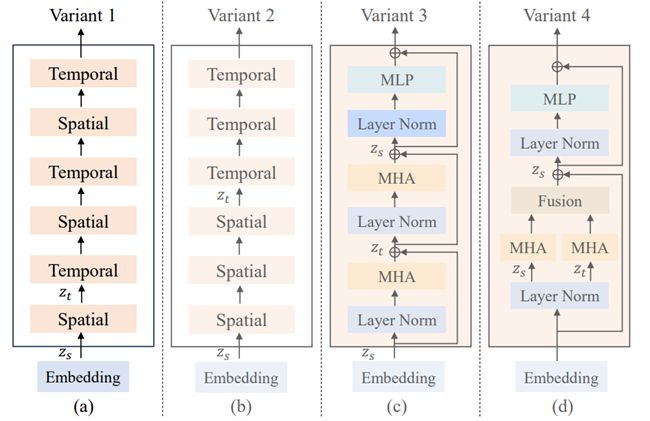
图来自官方Latte研究论文《Latte: Latent Diffusion Transformer for Video Generation》。
我将把实验结果留给您在他们的官方论文中理解,但总结一下,结合其他设计选择,变体1最终超越了其他变体。希望您喜欢阅读,感谢您的宝贵时间,继续实验吧!
推荐阅读:


FluxAI 中文
© 2026. All Rights Reserved