
最佳 AI 多模态模型
将近 2 年前
在这篇文章中,我们将讨论市场上各种开源和专有的多模态模型。

什么是多模态模型?
首先,让我们了解一下什么是多模态模型。多模态模型是能够同时理解和使用不同类型信息的人工智能系统,比如图片、文本、音频或视频。
关键点:
- 接受不同输入: 可以处理文本、图像、音频和视频。
- 信息结合: 将这些信息结合在一起,以提供更好的答案或创造更好的内容。
- 交叉学习: 学习不同输入(如图片和文字)之间的关系。
用途:
- 图像描述、问答、关于图片或视频的内容生成、从文本创建图像。
什么是 开源模型?
开源模型是任何人都可以免费使用、修改或分享的人工智能工具。代码是公开的,因此人们可以看到它是如何工作的,并进行改进。
关键点:
- 免费使用: 任何人都可以使用而无需付费。
- 可修改: 你可以改进或更改它。
- 共享: 人们可以共同努力使其更好。
开源模型的例子包括 LLaMA 和 Stable Diffusion。
Meta 的 LLaMA 3.2

描述: 开源的多模态人工智能,具备文本和图像处理功能,提供 1B、3B、11B 和 90B 参数变体,适用于不同设备。
应用: 适用于增强现实、视觉搜索和文档分析,处理图像描述和图表解读等任务。
显著特点:
- 多模态: 同时处理文本和图像。
- 本地处理: 较小的模型(1B、3B)可以在移动设备上运行,确保隐私。
- 性能: 在图像识别和推理方面表现出色,超越一些竞争对手。
Nvidia 的 Clara AI

描述: 专注于医疗保健的人工智能平台,利用先进的机器学习技术提升医学影像和诊断。
应用: 用于医学影像分析、药物发现和患者监测,以改善临床工作流程。
显著特点:
- 医学影像: 提供高精度工具以改善诊断。
- 医疗整合: 与现有医疗 IT 系统无缝集成。
- 实时处理: 实现实时影像数据分析,以加快医疗干预。
- 基于 Nvidia 的先进 GPU 架构,处理复杂的医疗数据。
BLIP-2(引导式语言-图像预训练)
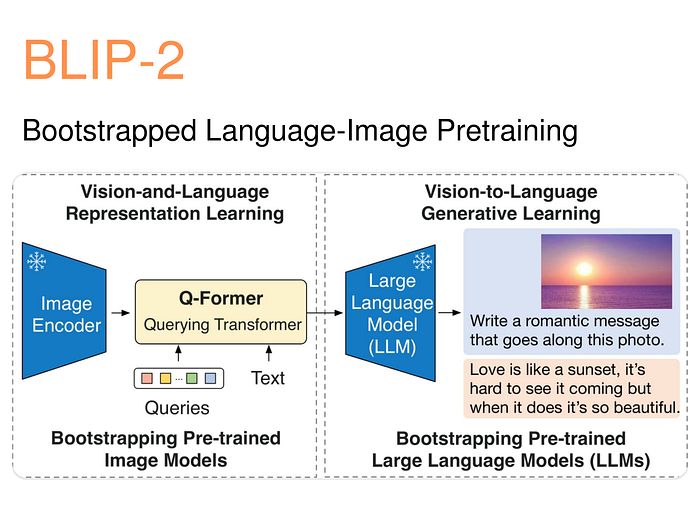
描述: 一种通过引导式训练方法整合语言和图像处理的多模态模型。
应用: 用于图像描述、视觉问答和结合文本与图像的人工智能应用。
显著特点:
- 引导式训练: 增强对文本-图像关系的理解。
- 高性能: 在需要视觉推理的多模态基准测试中表现出色。
- 灵活性: 可适应需要复杂视觉-文本交互的各个行业。
Stable Diffusion

描述: 一种强大的文本到图像模型,旨在从文本提示生成高质量图像,注重效率和创造力。
应用: 用于艺术创作、设计和各行业的创意内容开发。
显著特点:
- 效率: 优化以快速生成图像,所需计算资源最少。
- 创造灵活性: 允许用户控制生成图像的风格和细节。
- 高质量输出: 根据文本输入生成逼真且详细的视觉效果。
什么是 专有模型?
专有模型是由公司拥有的人工智能工具。你无法看到它们是如何工作的或进行更改,通常需要付费才能使用。
关键点:
- 由公司拥有: 只有公司控制它。
- 不是免费的: 通常需要付费才能使用。
- 无法更改: 你无法看到或更改它的工作方式。
一个例子是 ChatGPT 或 Runway Gen3。
GPT-4o Mini

描述: GPT-4 的一个较小、高效的变体,旨在实现强大的自然语言处理,减少资源需求,可以以较低成本进行微调。
应用: 适用于聊天机器人、虚拟助手和快速响应需求的轻量级自然语言处理任务。
显著特点:
- 效率: 优化以实现低延迟和最小资源使用。
- 多功能性: 适用于对话代理和内容生成。
- 强大的语言理解: 在理解和生成连贯响应方面保持高性能。
Runway Gen-3

描述: 一种用于从文本提示创建视频的人工智能工具,面向创意专业人士。
应用: 从文本和图像生成视频和创意内容。
显著特点:
- 高质量视频生成。
- 3D 渲染能力。
- 接受文本和图像作为输入。
OpenAI GPT-4

描述: 同时处理文本和图像,以实现高级推理和问题解决。
应用: 对话式人工智能、视觉理解、内容创作。
显著特点:
- 结合文本和图像输入。
- 高级推理和多模态交互。
- 支持跨模态的复杂查询和上下文理解。
Google Gemini

描述: 用于涉及语言、图像和空间推理的多模态人工智能。
应用: 视觉推理、机器人技术、医疗保健。
显著特点:
- 专注于空间推理。
- 在多模态任务中进行高级问题解决。
- 在医疗保健和机器人等多个领域的应用中具有多功能性。
Microsoft Kosmos-1

描述: 用于文本、图像和音频任务的多模态大型语言模型。
应用: 人机交互、多模态搜索。
显著特点:
- 处理文本、图像和声音。
- 现实世界应用,如文档理解和图像描述。
Anthropic Claude 3

描述: 从语言处理扩展到多模态任务,注重安全性。
应用: 聊天机器人和内容生成。
显著特点:
- 强调人工智能的安全性和伦理。
- 语言和视觉任务的整合。
- 强调用户友好的界面,以便于集成到应用中。
MidJourney

描述: 一种用于从文本生成艺术图像的人工智能模型,供创意人士使用。
应用: 艺术创作、视觉叙事。
显著特点:
- 艺术性和创造性的输出。
- 从文本生成高质量图像。
- 根据用户提示允许定制艺术风格和主题。
Suno AI

描述: 专有平台,专注于从文本生成 AI 驱动的音频内容。
应用: 文本转语音、音乐音效。
显著特点:
- 逼真的文本转语音生成。
- 从文本生成音乐和音效。
- 专注于音频合成,适用于各种应用。
如果你喜欢更多关于隐藏的人工智能宝藏的文章,请点赞并留言。
FluxAI 中文
© 2026. All Rights Reserved