
FLUX.1 [pro] 刚刚与成年人一起加入了 txt2img 表。
将近 2 年前
FLUX.1 [pro] 刚刚加入了成年人的txt2img表格
我也不确定是否有人预料到了这一点……
我们将逐步介绍如何使用它,以及它的渲染效果看起来如何——但首先,这是关于平台的一些家庭作业。截至本文发布,FLUX.1 文本到图像模型已经发布了24小时。FLUX.1 是一个开源的、快速渲染(是的,它很快),最先进的 GenAI 深度学习模型,由
这家公司有多新?(关注他们的)
.) 相当新的消息……在2024年8月1日,他们在其网站的“公告”部分发表了一份声明……


黑森林实验室团队包括:Andreas Blattmann, Andi Holmes, Axel Sauer, Dominik Lorenz, Dustin Podell, Frederic Boesel, Harry Saini, Jonas Müller, Kyle Lacey, Patrick Esser, Robin Rombach, Sumith Kulal, Tim Dockhorn, Yam Levi, Zion English FLUX.1 GenAI txt2img模型擅长于:
1 • 视觉元素: 复杂构图 • 逼真的有机纹理 • 多样的艺术风格 2 • 文本处理: 卓越的语言理解能力 • 精确的文本生成和定位 3 • 性能: 快速图像生成(比Midjourney V6标准速度快10倍) 作为比较的一点,Midjourney 有3种“速度”,这在技术上是图像生成的不同等待时间。 放松 * 动态等待时间,通常每个作业在0-10分钟之间。标准和专业计划的订阅者拥有无限的Relax生成次数。 快速 * 默认层级,使用订阅的每月GPU时间提供即时GPU访问。平均图像处理时间少于一分钟。基础计划会员每月可获得200次有限的快速生成。 涡轮增压 * 可以添加的参数,用于覆盖特定提示的默认生成速度。 标准、专业和超级计划的订阅者可以使用“/relax” + “/fast”命令在模式之间切换,或者在Alpha的提示栏下拉菜单中的‘速度’选项下切换它们。 使用 FLUX.1
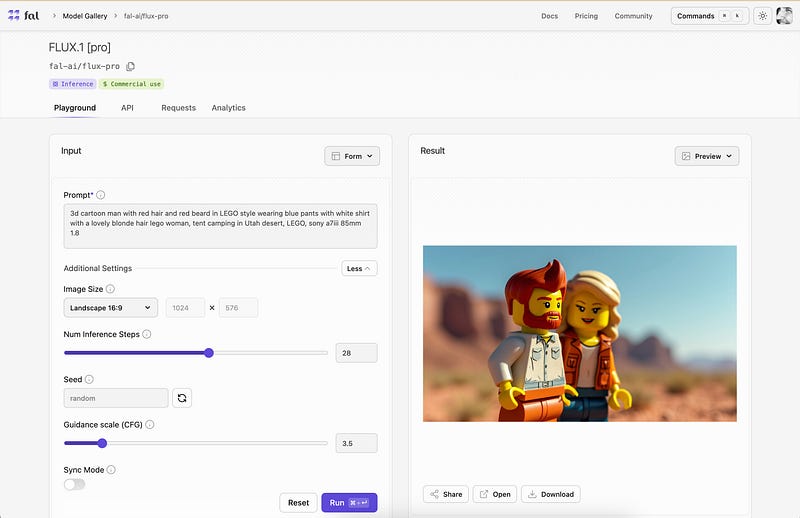
乍一看,对于Midjourney用户来说,这可能看起来有点令人困惑。它在某种程度上感觉有点像Stable Diffusion。我还没有探索API(尚未),但计划在不久的将来详细研究它。 游乐场
有两个关键区域 — 输入和结果。这相当直观。我们将在输入部分添加我们所有的提示要求。输入可以被视为表单(就像你在下面看到的那样)和JSON格式。
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。对于一个提示(prompt)的JSON表示,它可能包含一些基本的字段,例如提示的文本、提示的类型、以及可能的选项或参数。以下是一个简单的示例:
json { "prompt": { "text": "What is your name?", "type": "text", "options": { "case_sensitive": false, "required": true } } }
在这个例子中,prompt 对象包含了三个字段: - text:提示的文本内容。 - type:提示的类型,这里假设是 text,表示用户需要输入文本。 - options:一个对象,包含了一些选项或参数,例如: - case_sensitive:是否区分大小写,这里设置为 false。 - required:是否为必填项,这里设置为 true。
请注意,这只是一个示例,实际的JSON结构可能会根据应用的具体需求而有所不同。

在表单模式下,您需要考虑以下调整: 提示
生成你图片的基于文本的提示 图像大小
- 默认,正方形 (512x512),正方形高清 (1024x1024),纵向 4:3 (768x1024),纵向 16:9 (576:1024),横向 4:3 (1024:720),横向 16:9 (1024:576)
- 术语名称和结果大小之间存在一些差异。因此请注意数值比例。
- 您也可以选择“自定义”并设置自己的数值比例。我为4:5的比例(未列出)这样做了。如果您不确定它应该是哪个尺寸——做基本的数学运算。如果您想要一个4:5的比例,并且1024是您的第一个值——将其除以4并乘以5。(1024 / 4 x 5 = 1280) 数值推理步骤
执行的推理步骤数量。默认值:
28。范围是1到50。 * 如果你不知道这是什么,生成式AI文本到图像模型中的推理步骤指的是模型进行迭代的次数,以逐步细化并从初始噪声中创建最终图像。 这里是简短的解释: 1 • 初始状态: 这个过程从一个随机噪声图像开始。 2 • 迭代细化: 然后,模型经历一系列步骤,逐渐将这些噪声转化为与文本提示相匹配的连贯图像。 3 • 每个步骤: 在每个推理步骤中,模型: * 分析图像的当前状态 * 将其与文本提示进行比较 * 对图像进行小的调整,使其更接近匹配提示 4 • 持续改进: 每一步,图像都会变得更加清晰和详细。 5 • 最终输出: 在完成所有推理步骤后,模型生成最终图像。 推理步骤的数量通常可以由用户调整。更多的步骤通常会产生更高质量和更详细的图像,但也会延长生成时间。较少的步骤更快,但可能产生不够精细的结果。 不同的模型和实现可能有不同的最佳推理步骤数。有些模型可能只需要20步就能产生良好的结果,而其他模型可能需要50步或更多步骤才能受益。 种子相同的种子和相同的提示,给定相同版本的模型,每次都会产生相同的图像。 每次运行渲染时,都会生成一个随机的种子(默认情况下),但如果您愿意,也可以设置一个种子数字——用于自定义结果,或者使用已声明的种子以将之前渲染的结果应用于新的提示。 指导量表(CFG)
CFG(无分类器引导)量表是衡量您希望模型在寻找与提示相关的图像以展示给您时,与提示保持多紧密程度的指标。默认值:
3.5CFG的范围是1到20。 同步模式如果设置为true,函数将在生成并上传图像后才返回响应。这将增加函数的延迟,但它允许您直接在响应中获取图像,而无需通过CDN。 数字图像
生成图像的数量。默认值:
1应该明确写成“图像数量”……这样会更有意义。范围是1到4。 安全容忍度生成图像的安全容差级别。1是最严格,5是最宽松。默认值:
"2"太好了——那么渲染看起来如何?













一只老虎眼的极端特写镜头,直接正面视角。详细的虹膜和瞳孔。眼睛纹理和颜色的清晰焦点。自然光线捕捉真实的眼睛光泽和深度。“FLUX”这个词用大号白色画笔笔画在上面,具有可见的纹理。 * 图片尺寸: 竖屏 768:1024 * 推理步骤数: 28 * 指导量表(CFG): 3.5 * 图像数量: 1

我已经汲取了我丰富的经验——并将它们全部整合在一起,为面对这个人工智能新时代的创意专业人士提供资源。 *
— 资源和书籍 嘘……你知道吗,我写了一本书?实际上,我已经写了6本关于人工智能主题的书——但我最新的一本是在7月中旬发布的:
Midjourney — Back to Basics • Beginner’s Guide
立即获取您的副本,今天就开始精通Midjourney!

推荐阅读:






FluxAI 中文
© 2026. All Rights Reserved