
《揭秘ChatGPT:从概念到架构,数学解析全攻略(上)》
超过 1 年前
为什么理解 ChatGPT 架构需要先了解人工神经网络(ANN): ChatGPT 本质上是一个基于 Transformer 的模型,而 Transformer 模型的核心组件之一是前馈神经网络(Feed Forward Neural Network)。因此,理解神经网络的工作原理是至关重要的。此外,人工神经网络是人工智能的基础组成部分之一。基于这一思路,让我们开始探索人工神经网络。
人工神经网络受人类大脑启发: 人类大脑大约有 860 亿个神经细胞,这些神经细胞被称为神经元。神经元通过轴突相互连接。树突是神经元的树状分支,负责接收来自其他细胞的输入(例如来自感觉器官的输入),这些输入本质上就是电脉冲。这些电脉冲通过神经网络传递信息,并在神经元之间发送消息。这就是人类大脑工作的基本原理。下图展示了这一过程。
人工神经网络及其基本组成部分: 人工神经网络(ANNs)是一种受生物神经网络(如人类大脑)结构和功能启发的计算系统。它们通过学习数据中的模式和关系来解决问题。
人工神经网络由称为神经元或节点的相互连接单元组成,分为以下几层:
- 输入层:这一层接收原始数据(例如图像的像素值或数据集的特征)。该层中的每个节点对应一个输入特征。
- 隐藏层:这些层执行计算以提取模式或表示。每个神经元处理输入,应用权重和偏置,并将结果通过激活函数传递。
- 输出层:这一层提供最终结果,例如分类标签、预测值或概率分布。
想象一下教一个孩子识别猫和狗。输入层是孩子的感官输入(例如看到耳朵、毛发或尾巴)。隐藏层是孩子的思考过程(例如“尖耳朵=猫?”)。输出层是孩子的决定(“猫”或“狗”)。随着时间的推移和反馈,孩子会逐渐学会识别模式并做出正确的决定。
人工神经网络的工作原理: 要理解人工神经网络的工作原理,我们需要了解两个方面:前向传播和反向传播。在前向传播中,每个神经元接收输入并将其加权求和:z = w₁x₁ + w₂x₂ + ⋯ + wₙxₙ + b。其中,w₁, w₂,…, wₙ 是表示每个输入重要性的权重,b 是调整输出的偏置。接下来,输出 z 通过激活函数引入非线性:a = f(z)。常见的激活函数包括Sigmoid 和 ReLU。网络逐层计算输出。输入层将原始数据传递给第一个隐藏层。第一个隐藏层计算激活值并将其传递给下一层。这一过程持续进行,直到输出层生成最终结果。学习过程会计算损失。网络的预测结果与真实目标通过损失函数进行比较。损失 = 预测值与真实输出之间的差异。例如,回归任务中使用均方误差(MSE),分类任务中使用交叉熵损失。
在反向传播中,网络使用损失相对于每个参数的梯度来调整权重和偏置。这包括计算梯度(每个权重/偏置对误差的贡献);将这些梯度反向传播到网络中;并使用梯度下降更新权重。
Wₙₑᵥ = Wₒₗₙ - η⋅∂Loss/∂w;其中 η 是学习率。
为了理解梯度下降,我们来看一个简单的二次函数:
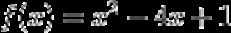
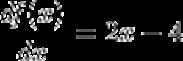
对于这个函数,假设学习率为 0.1,起始点为 x=9,我们可以手动计算前几步。以下是前三步的计算:
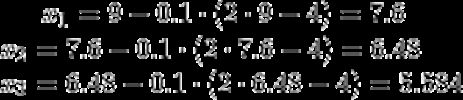
你可以看到梯度从 7.6 下降到 6.4,再到 5.5。网络通过多个epoch(完整遍历训练数据)来学习最小化损失并做出准确的预测。
人工神经网络的数学: 不多说,让我们直接进入人工神经网络的数学部分。以下是手写的数据:
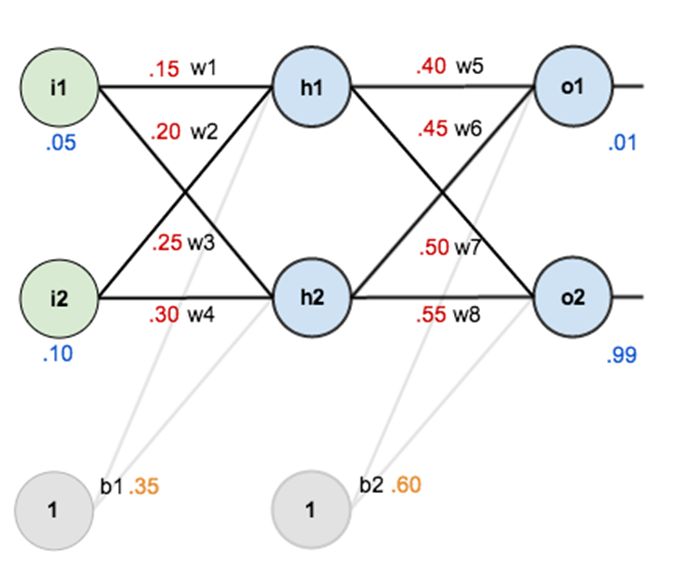
上面的深度神经网络包含一个输入层、一个隐藏层和一个输出层。它有两个输入 [x₁, x₂],三个隐藏单元 [h₁, h₂, h₃],以及两个输出 [y₁, y₂]。我们计算每个隐藏层神经元的总净输入,使用激活函数(这里使用逻辑函数)对总净输入进行压缩,然后在输出层神经元上重复这一过程。


梯度下降回顾: 批量梯度下降(Batch Gradient Descent)使用整个训练集,而小批量梯度下降(Mini-Batch Gradient Descent)使用小批量数据,随机梯度下降(Stochastic Gradient Descent, SGD)则每次使用一个训练样本来更新权重。在批量梯度下降中,你将数据分成批次,并在计算每个批次的误差后更新权重。
批量梯度下降 批量大小 = 训练集大小
随机梯度下降 批量大小 = 1
小批量梯度下降 1 < 批量大小 < 训练集大小。
在训练人工神经网络(ANN)时,理解批量大小、epoch 和迭代的概念至关重要。这些术语定义了训练过程中数据的处理方式。
批量大小:在更新模型权重之前一次处理的训练样本数量。如果你有 1000 个训练样本,批量大小为 100,那么你将数据集分成 10 个批次,每个批次包含 100 个样本。
Epoch:完整遍历整个训练数据集一次。如果你的数据集有 1000 个样本,一个 epoch 意味着模型已经看到了所有 1000 个样本一次。
迭代:基于一个批次对模型权重进行一次更新。如果你的数据集有 1000 个样本,批量大小为 100,那么完成一个 epoch 需要 10 次迭代。
我将提供一个示例,帮助你感受人工神经网络的训练过程以及输出结果。
给定条件:
- 数据集大小:10 个样本
- 批量大小:2 个样本
- Epoch 数量:3
数据集(特征和标签):
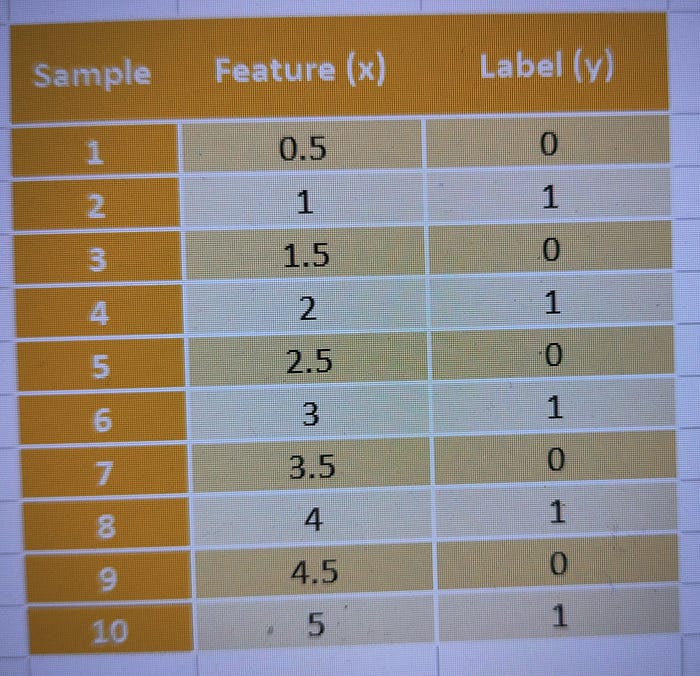
训练过程
批次形成:由于批量大小为 2,数据集被分成 5 个批次:
- 批次 1:样本 1, 2
- 批次 2:样本 3, 4
- 批次 3:样本 5, 6
- 批次 4:样本 7, 8
- 批次 5:样本 9, 10
Epoch 1(第一次遍历数据集):模型依次处理每个批次:
- 迭代 1:处理批次 1(样本 1, 2),更新权重。
- 迭代 2:处理批次 2(样本 3, 4),更新权重。
- 迭代 3:处理批次 3(样本 5, 6),更新权重。
- 迭代 4:处理批次 4(样本 7, 8),更新权重。
- 迭代 5:处理批次 5(样本 9, 10),更新权重。
在 5 次迭代结束时,模型完成了 1 个 epoch。
Epoch 2 和 3:模型对剩余的 2 个 epoch 重复相同的过程。每个 epoch 包含 5 次迭代(每个批次一次)。
总结
- 批量大小:2
- Epoch 数量:3
- 总迭代次数:总迭代次数 = 每个 epoch 的批次数量 × Epoch 数量 = 5 × 3 = 15
训练过程的可视化
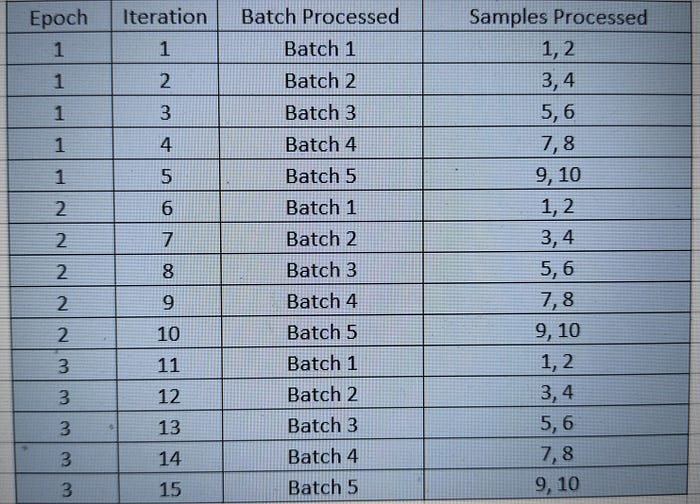
请注意,较小的批量大小会导致更频繁的权重更新,但可能会带来噪声。较大的批量大小提供更平滑的更新,但需要更多的内存。训练多个 epoch 确保模型多次从整个数据集中学习,从而提高准确性。而迭代次数定义了模型权重的更新次数。
如果你对反向传播的数学有任何疑问或想法,请告诉我。
希望这对你有帮助!
FluxAI 中文
© 2026. All Rights Reserved