
RNN有些东西是Transformers所没有的,你知道是什么吗?
超过 1 年前
RNN 有着变换器所不具备的优势
这也解释了为什么即使在理论上,LLM 的上下文长度也是有限的。
循环网络的独特优势
传统循环网络 (RNNs/LSTMs) 相较于现代的变换器、卷积神经网络,甚至是像 Mamba 这样的状态空间模型,拥有一种根本性的架构优势。这种优势也解释了在基于变换器的 LLM 中无限扩展上下文长度的一个主要挑战。
信息流的差异
关键的区别在于时间信息 (跨越文本标记) 或空间信息 (跨越视觉数据) 在网络中的流动方式:
- 在变换器、卷积网络,以及 Mamba 中:信息在不同位置之间流动需要多层网络的支持。单层的输出只能包含关注信息的聚合,而对这些聚合信息的转换主要发生在后续层中。
- 在 LSTMs 和 RNNs 中:单层本身可以顺序处理时间信息,内部状态可以在同一层中携带并转化来自更早位置的信息到更后的位置。
这种架构差异意味着 RNNs/LSTMs 在理论上能够以更少的层数更高效地建模序列依赖性,尽管这种优势需要付出相当大的代价。(LSTMs 甚至可能只需一层即可做到,而变换器至少需要两层)
训练悖论
不幸的是,这种特性一直是基于 RNN 系统的主要限制——它们的顺序特性严重限制了并行化,与变换器和卷积架构相比,极大地增加了训练成本。

对上下文长度扩展的影响
在开发具有越来越大上下文长度的 LLM 时,这一根本性约束影响所有架构:
像变换器这样的注意力系统在理论上应该支持通过几层实现无限的上下文扩展。然而,它们的有效感知受到值层向量维度的限制。由于这一信息瓶颈,注意力系统实际上更像是具有非常大但仍有限的有效感受野的卷积操作。
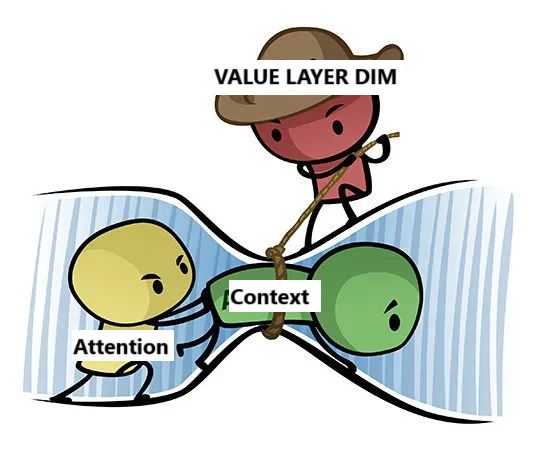
有效“感受野”通常小于变换器的完整上下文长度。这就是为什么增加层数能够提升在要求长上下文理解任务中的表现——每增加一层,模型处理远距离位置依赖的能力就会增强,类似于深层卷积网络捕捉更大空间上下文的方式。
即使是像 Mamba 这样的状态空间模型,尽管它们具有高效的序列建模设计,也需要类似的多层要求来完全处理时间信息,尽管它们相较于标准注意力具有更好的计算扩展性能。
而这正是为什么在变换器中对于极长上下文大小的理论限制(除了来自计算的实际限制)存在的原因 (即一个给定层数的变换器模型可能看起来能够处理无限个标记,但情况并非如此)
FluxAI 中文
© 2026. All Rights Reserved