
鲸鱼再出击!你准备好了吗?
超过 1 年前
鲸鱼再次发威
中国再一次尝试改变现状。

DeepSeek,这家几周前因对 NVIDIA 的历史最大单个股票下降 而引起争议(虽然是错误的)并且是中国最好的 AI 实验室之一,发布了新研究。根据近期发生的事情,全球正在对此给予高度关注。
当其意图明确且大胆时,尤其如此:一个算法突破,彻底挑战现代 AI 的现状。同时,再次证明西方是浪费的。
这种算法称为自然可训练稀疏注意力,它建议从根本上修改所有前沿模型的操作,有可能解锁“无限长度”的上下文窗口,这是大多数 AI 实验室尝试却未能实现的目标。
但如果有人能做到这一点,那就是这些家伙。让我们了解一下他们的最新进展。
从第一原理分析和 AI 的领域,充满了使用难以理解术语的假专家,二者通常并不结合。
但在这里,它们结合了。今天就订阅吧。
TheWhiteBox by Nacho de Gregorio - 在 AI 领域保持领先的通讯
语言的意义:现代 AI 背后的关键原则
关键基础知识
你有没有想过一个词是什么意思? 它是由两个要素派生而来的:
- 它的 内在意义(森林代表一组树木,而不是一群鸟),
- 以及它在环境中的意义(也就是说,“银行”根据上下文有两种不同的含义)。我称之为 上下文意义。
因此,虽然前者是默认提供的,但 AI 必须在接收序列后构建后者。因此,为了处理(理解)语言,语言模型执行一系列更新,用周围的上下文更新每个单词。
例如,在序列 “蓝色海盗” 中,“海盗”这个词 关注 “蓝色”,以融入其意义,以便在下一次迭代中,海盗不仅是一个留着胡子的、身上有异味的武装水手;它现在也是蓝色的。
因此,对于 ChatGPT 读取的每个序列中的每个单词,没有例外地执行这个过程。这个过程被称为全注意力,我们用它来构建词的上下文意义,这些词组合在一起,给文本序列的描述赋予意义。
为了执行这个过程,单词以表示这些单词的向量形式出现,其中向量中的每个数字可以被视为该单词的一个属性。例如,一个海盗的向量中可能有四个数字,例如 [3, 5, 8, 1],其中每个数字可能代表常见的海盗属性,例如 [‘国家’,‘赢得的战斗’,‘颜色’,‘有胡子/无胡子’]。
因此,当它关注“蓝色”时,表示“红色”的数字 8 可能变成 5,表示海盗现在是蓝色的。这是一个极其简化的解释,但这就是在第一原理下发生的事情。
为了加强这个概念,即概念向量的每个数字代表一个属性,看看下面的例子,我们可以结合这些向量并添加/减去特定特征,这使得这些概念变成其他概念,例如从“国王”中提取“男人”的属性,并加上“女人”,得到“女王”,类似于我们用红色变蓝的海盗所做的。
但为什么要使用向量呢?
除了这个组合的好处,__好吧,机器只能处理数字。此外,它允许我们比较单词之间的语义相似性。如果“狗”和“猫”有类似的向量(因为它们在现实生活中有多个共同的属性),这向机器表明它们是语义相关的(都是哺乳动物,家养的,四条腿,……)。
这是至关重要的,因为它允许机器理解现实世界概念之间的相似性。它将我们世界的复杂性转化为可以计算的数学操作;如果两个概念有相似的向量,这向 AI 发出了信号,表明它们在现实生活中是相似的。
这不是很美妙吗?
理解了这一点后,你现在也理解了任何前沿模型是如何工作的。在 AI 中遇到的所有其他复杂性都不再是问题,因为你在新闻上看到的每一个突破,在第一原理下,都归结为计算向量之间的语义相似性。
回到注意力机制,现在就能理解大语言模型是如何执行的。每个词在序列中搜索语义上相似的词,并通过“关注”它们来吸收它们的信息。这样,形容词找到它们的名词,副词找到它们的动词/形容词等等。
我为什么要告诉你这些? 好吧,看起来 DeepSeek 想要完全改变将我们带到今天的机制。
但为什么? 好吧,因为它有缺陷。
从全局到稀疏
注意力机制的问题在于序列越长,费用就越高——而且变得非常昂贵——因为每个新预测的单词必须关注越来越多的单词。
更糟的是,大多数注意力机制都是全局的,这意味着每个单词同等重要地关注序列中的每一个单词。
例如,如果你给 ChatGPT 发送一本书,第 12 章中的单词仍然会关注第 2 章中的每个单词,以构建它们的上下文意义,即便大多数单词没有有价值的信息可以分享。这是故意的,因为如果有可能需要分享一些重要内容,我们可以保证模型会注意到它。
例如,如果我们给 ChatGPT 发送一本阿加莎·克里斯蒂的书,在书的某一时刻,主人公可能会提到一个在早些时候发生的关键事件。如果注意力不是全局的,ChatGPT 就会基本忘记这一事实,从而失去上下文。
因此,我们面临一个十字路口。我们迫切需要降低注意力的成本,但我们又不想失去关注所有事物的能力,以便模型可以捕捉到即使是微小的细节。
因此,研究人员多年来一直尝试引入稀疏注意力,这是一个在精细程度和稀疏性之间进行权衡的方法,即不要求每个单词都关注上下文中的每个单词以构建其上下文意义。
然而,它们大多数都失败了。而 DeepSeek 可能终于解决了这个难题。
三步走的过程
正如前面提到的,大多数 AI 模型是全局注意力模型,即上下文中的每个单词都被平等对待。
但是我们可以改变这一点吗?
大规模扩展问题
总结上一部分的内容,每个单词向序列中的所有前面单词回望并询问:“你能给我提供什么信息?”然后,这些单词中的每个单词“回答”,并且单词决定应该更加关注哪些单词,从而利用所提供的信息丰富自身的上下文意义。
自然地,一些单词提供的上下文信息远比其他单词重要(例如,在第二章中赫尔克里·波洛提到的杀手的名字显然比第六章中的“呃”一词更重要),注意力通常在几个单词中崩溃。换句话说,尽管我们强迫模型执行全注意力,但结果大多是稀疏的(只有少数几个单词实际上起作用)。
问题在于,如果你的序列有一百万个单词在执行注意力的单词之前,它会“与”这百万个单词“交谈”,然后决定哪些单词有有价值的信息。这就意味着计算需求会大大增加,因为序列越长,计算量就越大。更糟的是,内存需求(在今天的讨论中我们将不涉及)也会激增。
这,朋友,就是为什么 ChatGPT 和其他 AI 产品不允许你输入无限长序列的最大限制因素之一;并不是模型不能处理它们,而是太昂贵了。
那么,DeepSeek 提出了什么?
使稀疏注意力成为可行的
问题是:我如何识别处理长序列的最佳方法,而不必逐个独立检查每个单词?
传统上,最常用的方法有两种:
- 其他架构如 状态空间模型(Mamba)。今天我们不讨论它们,但只需知道它们提议保持固定大小的状态或内存。对于每个新读取的单词,模型会询问信息是否值得记住。我们保持低内存需求,但这与全局注意力进行权衡。
- 稀疏注意力方法,它们压缩注意力过程。
- 不幸的是,第一类存在严重的性能问题。模型被迫具有固定大小的内存,最终会忘记关键内容。
- 至于后者,其理论效率提升往往未能在现实中得到体现。
DeepSeek 的方法 属于第二类,但与以往的提议根本不同。它将注意力分为三部分:压缩、选择和 滑动窗口。
我将先解释这三个组件,然后用一个类比来帮助理解,所以请耐心等待。
- 压缩: 它将单词序列分割成块,将每个块中的内容压缩成单一的信息摘要。
- 选择: 当然,摘要总是意味着信息的损失。因此,它添加了一个选择机制,选择最重要的块。如果选择了某个块,则会重新读取整个块(这意味着与每个单词都执行注意力)。
- 滑动窗口: 大多数文本具有时效偏好,这意味着最新的单词通常对于序列中的最新单词更为重要。例如,要理解第 12 章,第 11 章中的信息通常比第 5 章中的信息更重要。因此,在最近单词的窗口内,关注所有单词。
当检索到三组信息时,它们会被组合并分享给单词,防止其关注上下文中的每一个单词。
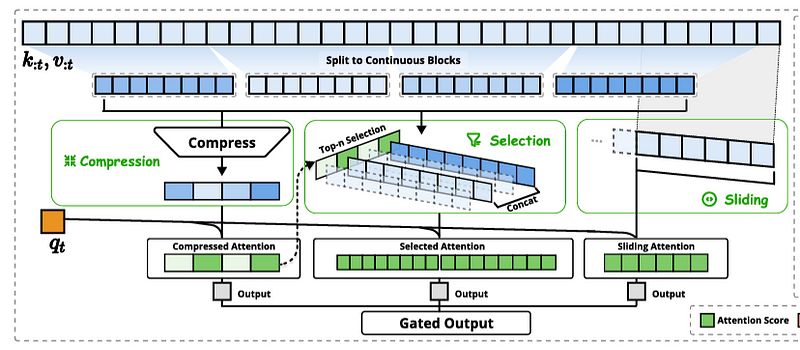 NSA 的概述。来源
NSA 的概述。来源
因此,简而言之,对于希望构建其上下文意义的每个单词,我们:
- 将之前的上下文分解成块,创建每个块的摘要,然后提供给它。
- 同时,每个块根据其重要性被“排名”,那些得分较高的块在单词层面受到关注。
对于那些技术较强的你们,压缩步骤的注意力得分在选择过程中用于排名。
- 此外,同时,最近的块仍然会受到关注,因为时间更接近的单词通常提供更有上下文价值的信息。
- 最后,所有信息向量根据相关性打分(某些单词将从摘要中受益最多,某些单词需要更细致的注意力信息)并用于更新单词的上下文意义。
通过这种方式,尽管我们在执行稀疏注意力,某些单词没有单独被关注(存在失去上下文的风险),你仍然有很大机会不会错过任何重要内容。
为此,我们可以使用书籍类比:
- 压缩 方法将书分成章节,并将每一章节的信息压缩成摘要(即“在第 3 章中发生了这一事件”)。
- 对于那些对于当前章节看来更为相关的章节,这些将被 选择 并仔细阅读,以防需要记住任何重要细节(即,在第 12 章中,波洛回忆了关于犯罪之夜的思考,详细叙述在第 6 章中,因此会完全检索第 6 章)。
- 对于最近章节内的 时效窗口 ,它仍然会仔细阅读(即,如果我们在第 13 章,则由于时间偏好完全读取第 12 章)。
最后,所有信息被合并并提供给单词,这样它可以借助处理跨越数百万字的信息更新其上下文意义……而不必关注上下文中的每一个单词。
美妙又合逻辑,是不是?而且最棒的是……它确实有效。
结果与硬件感知
下图显示,使用 NSA 训练的模型与全局注意力(全注意力)相比,其性能相当或更高,同时速度和成本大幅提升。
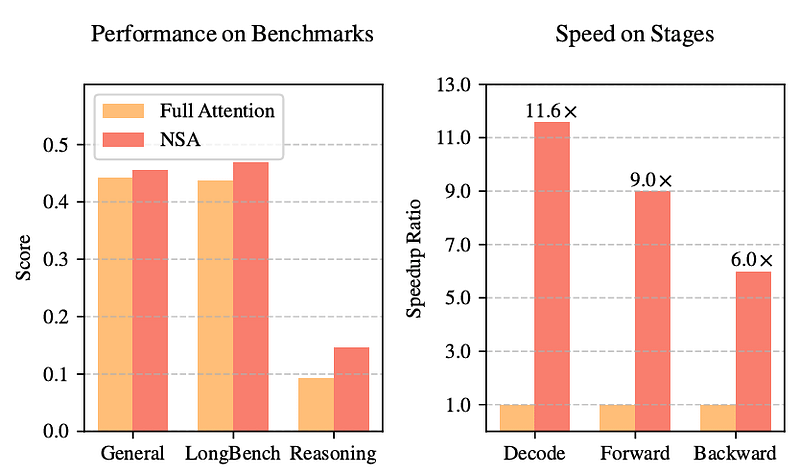
但为什么故意忘记一些上下文信息的方法,表现超过全注意力方法?
我们还不完全确定,但我的直觉是这个算法找到了信号与噪音的最佳平衡点。
用通俗点的话来说,NSA 似乎能剔除噪音,让模型专注于重要的事情,且成本更低。
但 DeepSeek 还没有结束,最重要的原因是这个方法是 “硬件感知的。” 大多数稀疏注意力方法选择在上下文中关注的单个令牌。这对于 GPU 来说是次优的,因为按设计,从连续块中获取单词时性能最佳。
通俗地说,当 GPU 从上下文中检索整块内容以处理时,表现最佳,而不是选择单独的、隔离的数据,后者需要更多的内存读取。用简单的话来说,这个算法最小化了 GPU 读取内存的次数,从而增加延迟。换句话说,它确保连续数据,比如同一章节中的单词,被一起处理,使得整个过程比传统的方法快得多。
这可能比 R1 更重大。
如果 NSA 兑现它的承诺,这无疑是 DeepSeek 迄今最大贡献,甚至超越 DeepSeek 的 v3 和 R1。我们都知道那次市场发生了什么……
如果 AI 最终征服了长上下文数据,使用案例和价值的激增可能会是巨大的。
而且,再一次,突破来自中国。
这让你对西方的看法有什么影响呢?
如果你喜欢这篇文章,我在我的 LinkedIn 上以更全面和简化的方式分享类似的观点。
推荐阅读:






FluxAI 中文
© 2026. All Rights Reserved