
本地运行HunyuanVideo!腾讯开源视频生成模型发布(超越Sora?)
超过 1 年前
AI 视频领域的激动人心的消息!这篇文章将为你提供 概述、提示技巧,以及如何在本地运行 HunyuanVideo 的指南。我花了很多时间测试它,所以请为它鼓掌、分享并关注我的账号!
腾讯开源了 HunyuanVideo!他们称其为腾讯的 Sora。
1300 亿 参数 —— 这是目前参数规模最大的开源视频生成模型。模型权重、推理代码和模型算法都已上传到 GitHub 和 Hugging Face,没有任何保留(链接在文章末尾)。
油管。我在那里上传了很多技术教程视频。我还开通了一个 newsletter,如果你感兴趣,请注册!
腾讯 Hunyuan 视频生成的关键特性:
超真实质量:该模型生成的视频具有高清、逼真的视觉效果,适用于广告和创意视频制作等工业级商业场景。
高语义一致性:用户可以指定主体外观、角色概念等细节。模型能准确反映文本内容。
流畅动作:它能够生成大幅度的合理动作,镜头运动流畅,符合物理规律,不易失真。
原生镜头切换:模型内置支持对同一主体的自动多角度拍摄,增强了视频的叙事质量。
提示词写作技巧:
提示词可以非常灵活。以下是腾讯提供的指南。
方法 1:主体 + 场景 + 动作
方法 2:主体(描述) + 场景(描述) + 动作(描述) + (镜头语言) + (氛围) + (风格)
方法 3:主体 + 场景 + 动作 + (风格) + (氛围) + (镜头运动) + (灯光) + (镜头大小)
多镜头生成:[场景 1] + 镜头切换到 [场景 2]
两个动作:[主体描述] + [动作描述] + [过渡词如“然后”或“过了一会儿”] + [第二个动作描述]
技术亮点:
根据官方评估,Hunyuan 的视频生成模型在文本-视频一致性、动作质量和视觉质量方面表现出色。以下是三个关键技术点:
文本编码器:适配最新的多模态大语言模型,增强语义理解和细节执行。
视觉编码器:支持混合图像/视频训练,提高压缩和重建性能,尤其适用于小脸和高速镜头。
全注意力机制:从头到尾使用统一的全注意力机制,增强视频帧和镜头切换的流畅性和一致性。
本地运行
目前,运行它需要大量资源(我相信社区很快会优化它)。

由于 几乎所有消费级 GPU 的显存都小于或等于 24GB,最佳选择是从云服务提供商那里租用 GPU。让我们租一个吧!我使用了 AWS 的 EC2 服务。我测试了一些实例类型(规格类型),发现要运行 HunyuanVideo 544p,最低需要的规格是 G6e.2xlarge,它具有:8 个 vCPU、1 个 NVIDIA L40S Tensor Core GPU(48 GB 显存)、64 GB 内存(用于加载模型)。

NVIDIA L40S Tensor Core GPU
我使用了 Ubuntu OS 24.04。GitHub 页面包含了安装步骤和模型下载步骤。在我的测试运行中没有发现任何问题。
git clone https://github.com/tencent/HunyuanVideo
cd HunyuanVideo
# Linux 安装指南
# 我们提供了一个 environment.yml 文件用于设置 Conda 环境。Conda 的安装说明可以在这里找到。
# 我们推荐使用 CUDA 11.8 和 12.0+ 版本。
# 1. 准备 conda 环境
conda env create -f environment.yml
# 2. 激活环境
conda activate HunyuanVideo
# 3. 安装 pip 依赖
python -m pip install -r requirements.txt
# 4. 安装 flash attention v2 以加速(需要 CUDA 11.8 或更高版本)
python -m pip install git+https://github.com/Dao-AILab/[[email protected]](https://www.freedium.cfd/cdn-cgi/l/email-protection)
它使用虚拟 Python 环境或 Docker 镜像。推理代码很简单:
python3 sample_video.py
--video-size 544 960
--video-length 129
--infer-steps 50
--prompt "一只猫在草地上行走,写实风格。"
--flow-reverse
--use-cpu-offload
--save-path ./results
速度如何?不幸的是,并不快。
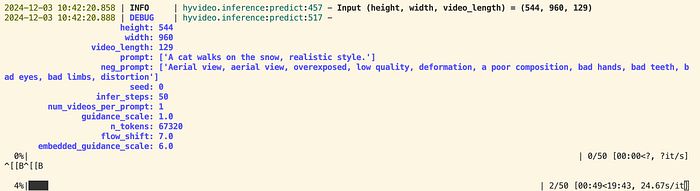
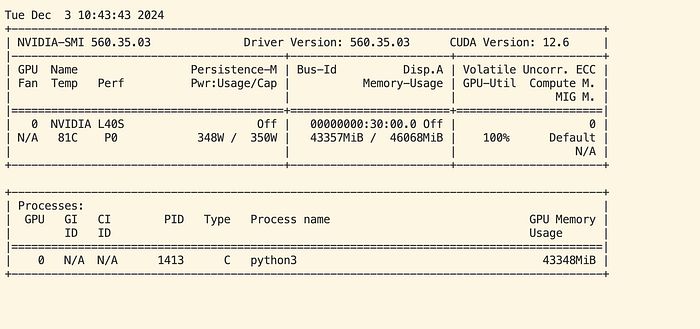
从上面的截图可以看出,1 次迭代需要 24.67 秒。50 步至少需要 20 分钟。以下是 GPU 监控的截图。它确实需要至少 40GB 的显存。
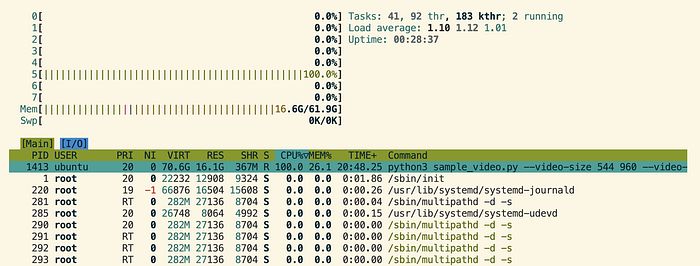
以下是推理期间的 CPU 和 RAM 截图。
它需要很多耐心。但我相信很快就会有所改进。让我们希望 24GB 的 GPU 也能运行它!
更多信息请访问:
Github: https://github.com/Tencent/HunyuanVideo
项目页面: https://aivideo.hunyuan.tencent.com/
Huggingface:
tencent/HunyuanVideo · Hugging Face 我们正在通过开源和开放科学推动和民主化人工智能的旅程。huggingface.co
推荐阅读:

FluxAI 中文
© 2026. All Rights Reserved