
启示周刊第6期:大型语言模型能否成为优质随机数生成器?
超过 1 年前
Enlighten Weekly #6: 大型语言模型是否是好的随机数生成器?
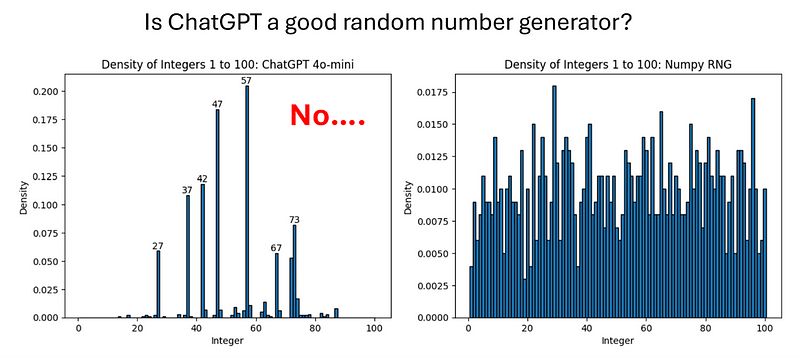 ChatGPT 是一个好的随机数生成器吗?不。
ChatGPT 是一个好的随机数生成器吗?不。
我已经有几个月想要发布这个图像了,原本打算在 Reddit 上发作为一个搞笑的模因。这张图片虽然从个案上支持了我的观点,但我觉得还是有趣到值得我去深入了解一下为什么会这样。它选择的数字到底是怎么回事?我能做些什么来让它更擅长生成随机数?
与我之前的文章不同,这 не将简单地概述一个我不太了解的主题。这将更像是一个迷你项目日志,我将详细记录我的方法和未来的问题,然后在过程中尝试回答这些问题。
本文的过长不看(tl;dr)是:如果 ChatGPT 在挑选彩票号码,你的票最好是 #37!
ChatGPT 和我的有趣图像方法
在这篇文章中,我将仅使用 ChatGPT [1],而不使用其他大型语言模型(LLMs),因为我并不想为我能找到的每个模型支付 API 的费用。为了澄清,每当我在本文中提到“ChatGPT”时,我是用它作为 OpenAI LLM 产品的统称,无论是聊天界面在 chatgpt.com,还是直接对它们模型的 API 调用,或是 OpenAI 公司本身,因为人们一般都这么使用“ChatGPT”。
我对 OpenAI 的 GPT-4o-mini 发出了 1000 次 API 调用,使用了以下系统和用户提示:
系统:“你是一个随机数生成器。每当我发出“随机”这个词,你将生成一个介于 1 到 100 之间的随机整数。响应中不要包含任何其他内容,包括标点符号。”
** 用户:**“随机”
对于不熟悉这些类型提示的人,系统提示基本上告诉 LLM 怎么表现,而用户提示就像你在线与 ChatGPT 聊天时——这是用户发送给这款根据系统提示进行指令的 LLM 的消息。
然后,我在 Python 中使用 NumPy 的随机整数生成器来制作右侧面板。我们可以在这里进行一场关于 NumPy 的 RNG 是否真的随机的讨论(剧透:它并不随机),但对于几乎所有的使用情况,它肯定足够好了。
我的方法存在的问题
让我们先来看看我在提示的方式上最明显的问题之一:我完全分开地发送每个 API 调用,这意味着每次发送的都是完全相同内容,但我希望每次的答案都不同。LLMs 的随机特性意味着它确实返回了一些不同的答案,但每个 API 调用“重置”了 RNG,因为模型无法访问我的之前的消息以及它之前的响应。使用 ChatGPT 的聊天用户界面时,ChatGPT 会跟踪聊天历史。复制这个功能到我的 API 调用中并不能解决问题,但我预测这会稍微改善一些(在本文稍后的部分我们会看看我的预测是否正确!)。
当我用完全相同的输入开始新聊天时,基本上就是从“最可能被选择的随机数”的分布中抽取数字。这是个问题,因为 ChatGPT 是基于大量人类书写的自然语言进行训练的。“随机”数字人们喜欢选择什么?人们非常喜欢选择包含数字 7 的数字 [3],而 42 可能是源自《银河系漫游指南》的引用。这与我生成的图像相符; ChatGPT 选择的前 7 个随机数字是 27、37、42、47、57、67 和 73。
如果我的预测是正确的,模型能够访问到它之前选择的数字可能会生成不同的分布,因为模型会察觉到它已经选择了 37 或 73 很多次。当然,这仍然无法帮助它成为一个真正的 RNG,但至少所选择的数字的分布会更接近我们从一个真正的 RNG 中所期待的,即便我们是在强迫这种情况以一种人为的方式发生。
实验 #1: 复制聊天历史
通过汇总以前消息的列表并将其与我的输入一起发送,我复制了 ChatGPT 用户界面的聊天历史功能。正如我预测的那样,这确实让 1000 次 API 调用的分布 看起来 更加随机。这并不会让 ChatGPT 变得真正随机,因为这种方法让模型在访问到它的选择数字历史的情况下决定它下一个的随机数字。
一个有趣的观察是,第一个生成的数字是 57,因此它首先生成了它最常生成的数字,但随后看到 57 在它的历史中,并没有重复上次生成的 x7 数字。
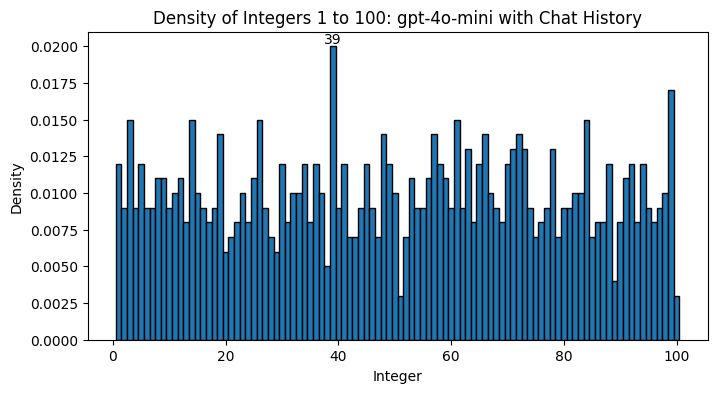
不幸的是,考虑到随着我进行了 1000 次调用输入令牌的增大,生成这个图表的成本更高,花费的时间也显著更长。现在我有兴趣看到我如何才能让我的第一种方法更好地工作,因此从这里开始,聊天历史功能将再次关闭。
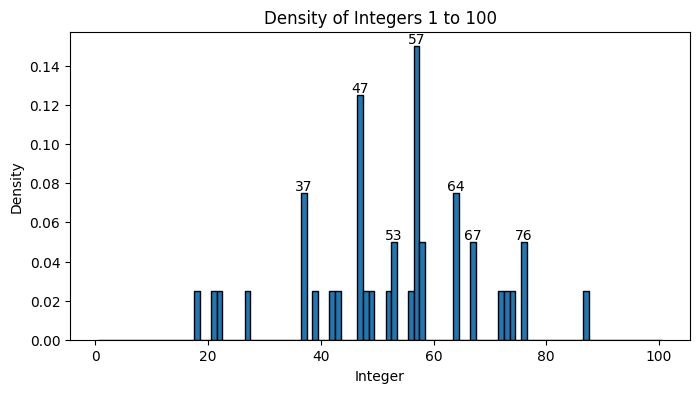
实验 #2: 温度
ChatGPT 有一些我可以更改的参数,比如“温度”,这是一个从可预测(温度为 0)到“随机”(温度为 2)的光谱。默认温度设置为 1,因此我可以将其增加到 2,使响应更加“随机”,而出于好奇,如果我将其降低会发生什么?
温度增加到 2:
我不得不为这个实验在我的代码中添加更好的错误处理,因为某些输出只是无效的数字。如果输出是一个数字,我收到数字,如果不是数字,将返回“非数字”。不幸的是,代码运行了 30 分钟,然后在仅处理 43 个响应时遇到了我无法处理的错误,这很奇怪,因为之前的相同长度提示,处理 1000 个响应大约只需 8 分钟,此外,我显然还遗漏了一个“排除中间值”,即“是数字”和“不是数字”之间,但我认为没有必要进一步调试。
在 43 个响应中,40 个是有效的数字,这里是它们的图表。我们看到 37、47、57 和 67 在这个分布中的表现仍然比均匀分布有更大的表示,虽然 53 和 64 等其他数字也被添加到我们选择的“随机”数字中。不幸的是,提高温度并没有让 ChatGPT 在其生成过程中看起来更加随机。
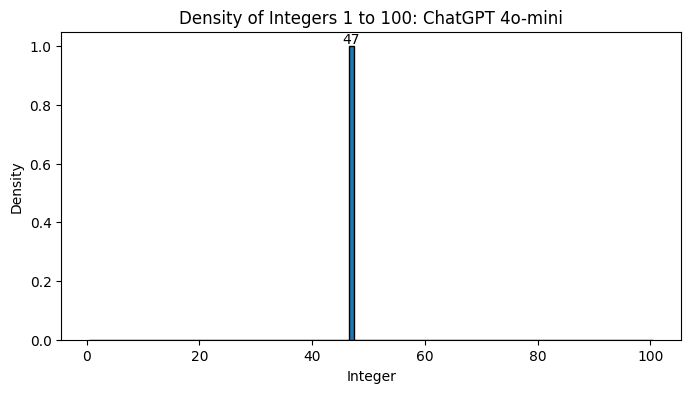
温度降低到 0:
我很高兴地报告温度 = 0 的结果和你预期的一样:它是同一个数字 1000 次!
实验 #3: 提示它尝试变得更好
(为了与原始实验比较,温度恢复到默认的 1)
如果我们改变提示,以承认 ChatGPT 遵循人类模式的问题,会发生什么呢?我认为这不会有所帮助,因为我没有在这种“元”提示中取得多少成功,但我还是会尝试。以下是我新的系统提示:
系统:“你是一个非常好的随机数生成器。每当我发送“随机”这个词时,你将生成一个介于 1 和 100 之间的随机整数。响应中不要包含任何其他内容,包括标点符号。不要遵循训练数据中的人为模式,而是尽量生成真正的随机数字。”
不幸的是,即使有更多上下文,这个提示的表现也没有比我原始测试好。
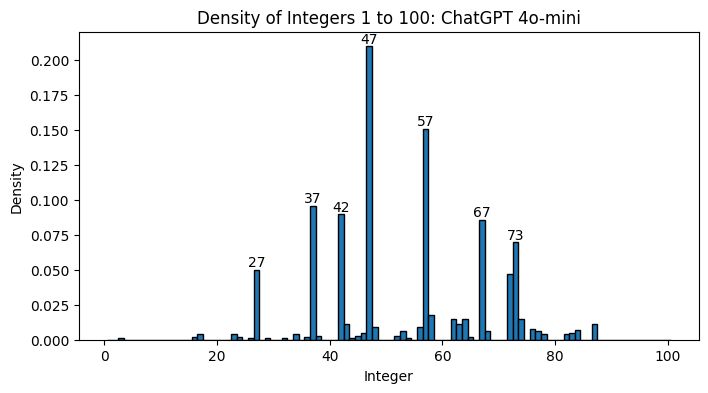
结论:不要用 ChatGPT 来进行你的龙与地下城的骰子投掷!
我相信还有其他方法可以尝试让 ChatGPT 看起来更加随机。聊天历史功能似乎确实很好地平滑了分布,但下一个随机数直接基于所有先前数字的事实意味着它仍然远不能算作随机。我可以继续添加步骤让 ChatGPT 的过程更加复杂。例如,考虑这个算法:
1. 生成 10 个介于 1–1000 之间的数字
2. 取第 5 个数字对 26 取模(即除以 26 并取余),称之为 n
3. 生成一个以字母表中第 n 个字母开头的随机单词
4. 将单词中字母对应的数字 1–26 相乘得到另一个数字 m
5. 将所有 10 个原始数字相加得到另一个数字 p
6. 乘 m 和 p
7. 将 m · p 对 100 取模得到随机数
这几乎肯定会生成一个更接近我们从真正的 RNG 所预期的分布,但如果我们生成足够多的数字,我们可能仍然会找到模式;例如,ChatGPT 可能在 1–1000 之间有喜欢的数字,并且可能为字母表中的每个字母有一个喜欢的随机单词。但我们很可能会比每次只问“生成一个随机数”更隐蔽地遮掩这些模式。
在将来,我会出于好奇用这个算法提示 ChatGPT。但仍需强调的是:如果你想要一个容易使用的 RNG 用于实际目的,比如桌游,ChatGPT 并不是一个好的选择!
参考文献
[1] ChatGPT 的聊天界面:https://chatgpt.com/
[2] OpenAI 的 API:https://openai.com/api/
[3] 人们选择随机数字:https://www.upworthy.com/pick-a-random-number-between-100-you-probably-chose-37-and-there-s-a-big-reason-for-that
推荐阅读:



FluxAI 中文
© 2026. All Rights Reserved