
🎬 Meta电影音频生成器揭秘:第五部分,你绝对想不到的幕后技术!🎧
超过 1 年前
引言
Movie Gen Audio 是一款生成式 AI 模型,它能够根据输入的视频生成音频,或者在给定视频和部分音频的情况下扩展音频。此外,用户还可以通过提供或添加文本提示来控制生成或扩展的音频。
对于一段视频,其音频内容可能是多样的。音频可能来自场景内,也可能是为了强调某些内容而添加的场景外音,或者仅仅是角色对话时的背景音乐等。
为了更清晰地说明,他们通过表格对视频中可能出现的音频进行了分类。

与视频相关的不同类型的声音
在收集的数据集中,他们重点关注了以下几类音频,并忽略了其他类型:
场景内声音(Diegetic General Sounds)
- 屏幕内的声音,如海浪拍打声
- 屏幕外的声音,如狗吠声,这些声音自然发生在场景环境中
- 与可见动作或环境匹配的音效(如脚步声或自然环境声)
非场景内音效(Non-diegetic Sound Effects)
- 罐头笑声(后期制作中添加的)
- 紧张感增强音效(用于营造紧张气氛的音效)
- 后期制作中添加的音效,这些音效并非自然发生在场景中
器乐音乐(Instrumental Music)
- 后期制作中添加的背景音乐
- 非人声的音乐配乐和主题曲
- 支持情绪并与场景动作对齐的音乐
非场景内音效与器乐音乐的关键区别在于,非场景内音效是为特定戏剧性时刻添加的独立音效元素,而器乐音乐则是为整个场景提供连续的音乐伴奏,设定整体的情感基调和氛围。
你可以观看《爱乐之城》来体会音频如何让一个简单的故事变得美丽,并理解我们所说的不同类型音效。
现在你已经知道 Movie Gen Audio 模型能够生成/扩展音频,以及它可以生成/扩展的音频类型,接下来让我们关注它是如何做到这一点的。和往常一样,我们将通过 FTI 架构来剖析技术细节。请阅读这篇博客,了解我所说的通过 FTI 架构理解的含义。
所有代码示例均使用 Code Sonnet 3.5 进行了增强
特征管道
思考一下我们需要训练这个模型的数据。它应该是大量的样本,每个样本必须包含视频、音频以及相应的音频描述。
但音频的类型是多样的。你如何识别或过滤出包含我们所需音频(场景内声音、非场景内音效或器乐音乐)的视频?如果你被分配了为这个模型收集数据的任务,你可能会大规模收集带有音频的视频(同时获取音频描述的情况很少见)。以下是 Meta AI 团队为获取所需数据所采取的步骤。
初始过滤
原始视频/音频数据 ↓ 时长过滤(4–120秒) ↓ 分辨率过滤(≥480像素) ↓ 静态内容移除 ↓ 文字覆盖移除(OCR,即移除包含文字的视频) ↓ 去重
他们使用了复制检测嵌入来移除重复视频(去重)。使用机器学习模型来训练新的机器学习模型所需的数据!!
2. 音频分类
过滤后的数据
↓
音频事件检测(AED)
- 标记 527 种可能的音频事件
- 映射到基本类别(语音/音乐/声音)
↓
音频-视觉对齐评分(CAVTP)
- 测量音频-视频嵌入之间的余弦相似度
- 根据阈值分类为场景内/非场景内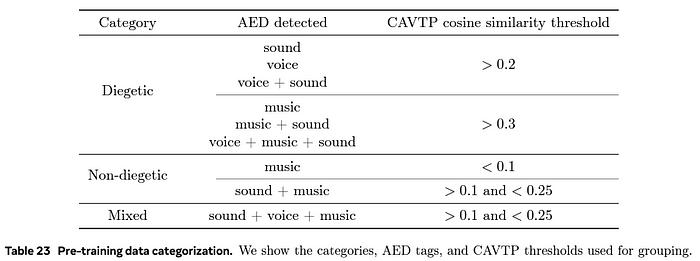
AED 模型(一种机器学习算法)可以根据输入的音频将其分类为 527 个类别(Audioset 本体)。
CAVTP(对比音频-视频-文本预训练)评分用于帮助分类视频中的音频是场景内还是非场景内。CAVTP 评分是通过 CAVTP 模型中的音频和视频嵌入之间的余弦相似度来衡量的。
我们得到了所需的数据,即我们有了一个包含视频和所需音频类型(场景内、非场景内和器乐)的数据集,供模型训练。剩下的就是生成音频描述。然后我们的特征库就完全准备好了。
3. 元数据生成
质量评分:
复制处理后的片段
↓
音频质量模型(1–10 分)在此过程中使用了一个深度学习模型。
音频质量模型:用于评估音频的质量
B. 字幕生成:
复制合格的片段
↓
音频事件描述
↓
音乐风格描述(如果适用)
↓
语音/音乐存在标签在此过程中使用了两个深度学习模型。
音频字幕模型:根据音频生成字幕
音乐字幕模型:与 AED 结合(以区分语音和音乐的存在),包含音乐的音频使用此模型生成字幕。
以下是他们通过执行上述两个过程(质量评分和字幕生成)创建的描述示例。

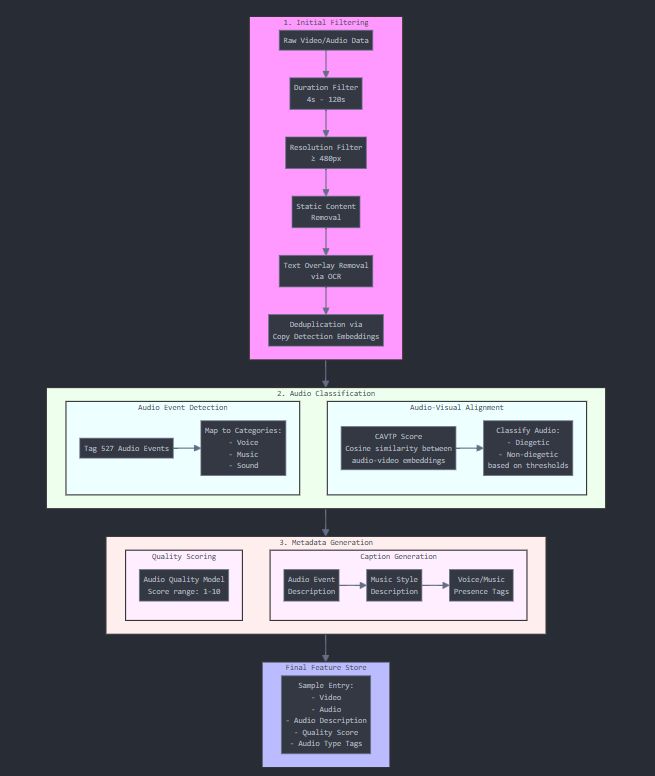
Movie Gen Audio 的特征管道概述
以下是所有训练数据(包括测试和验证数据)最终在特征库中的组织方式。因此,我们的特征库中有多个样本,每个样本包含视频、音频和相应的音频描述。
训练数据组织:
A. 时长结构:
复制最终数据集
↓
10 秒音频块(主要)
↓
30 秒音频块(补充)
(训练比例为 5:1)B. 音量分布:
复制主要类别:
- 纯声音:约 1 亿个样本
- 音乐组合:每个约 1000 万个样本
- 语音组合:每个约 1000 万个样本
总计:约 1 亿个样本 / 约 100 万小时训练管道
类似于我们通过一个数据样本学习 Movie Gen Video 模型的训练管道,让我们也通过同样的方式来理解这个模型。我将提供一个粗略的 Python 脚本,然后我们将理解其工作原理。
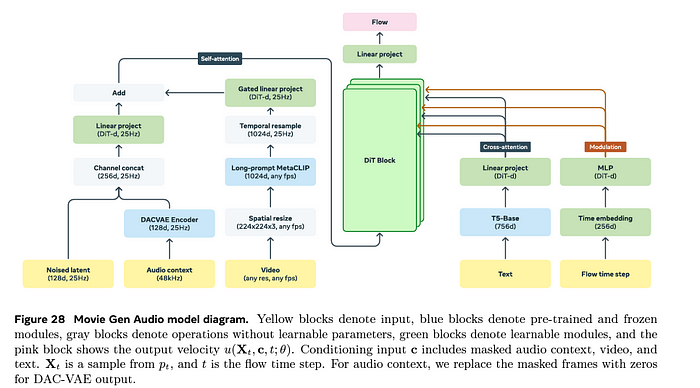
Movie Audio Gen 模型的架构
def process_single_sample(self, video, audio, text_caption, flow_time_step):
"""
通过 Movie Gen Audio 模型处理单个训练样本
参数:
video: 输入视频张量,形状为 [10s * 30fps, 3, H, W] = [300, 3, 720, 1280]
audio: 输入音频 48kHz,形状为 [480000, 2](10s * 48000Hz,立体声)
text_caption: 文本描述
flow_time_step: 当前流时间步长 t(标量,介于 0 和 1 之间)
"""
batch_size = 1 # 对于单个样本
# 1. 生成噪声潜在表示
# DAC-VAE 将 48kHz 降低到 25Hz:10s * 25Hz = 250 个时间帧
clean_audio_latent = self.dac_vae_encoder(audio) # 形状:[1, 250, 128]
# 从标准正态分布中采样噪声
noise = torch.randn_like(clean_audio_latent) # 形状:[1, 250, 128]
# 在时间步长 t 处创建噪声潜在表示
noised_latent = (flow_time_step * clean_audio_latent +
(1 - (1 - 1e-5) * flow_time_step) * noise) # 形状:[1, 250, 128]
# 2. 音频上下文
audio_context = self.create_audio_context(clean_audio_latent) # 形状:[1, 250, 128]
# 3. 合并噪声潜在表示和音频上下文
# 沿通道维度连接
combined_audio = torch.cat([noised_latent, audio_context], dim=-1) # 形状:[1, 250, 256]
# 4. 处理视频分支
# 空间调整:224x224 是许多视觉模型的标准尺寸
resized_video = self.spatial_resize(video) # 形状:[300, 3, 224, 224]
# MetaCLIP 特征
video_features = self.metaclip(resized_video) # 形状:[300, 1024]
# 从 30fps 时间重采样到 25Hz 以匹配音频
video_features = self.temporal_resample(video_features) # 形状:[250, 1024]
# 5. 主处理分支
# 通道投影合并的音频
latent_proj = self.channel_proj(combined_audio) # 形状:[1, 250, 256]
# 线性投影到 DiT 维度(假设 DiT-d = 4608,如论文中所述)
features = self.linear_proj_dit(latent_proj) # 形状:[1, 250, 4608]
# 将视频特征投影到相同维度
video_proj = self.video_linear_proj(video_features) # 形状:[250, 4608]
# 门控线性投影
gated_features = self.gated_linear_proj(
features,
video_proj
) # 形状:[1, 250, 4608]
# 自注意力
attention_output = self.self_attention(gated_features) # 形状:[1, 250, 4608]
# 5. 条件分支
# 文本:T5-Base 生成 756 维嵌入,最多 512 个标记
text_features = self.t5_encoder(text_caption) # 形状:[1, 512, 756]
text_proj = self.text_linear_proj(text_features) # 形状:[1, 512, 4608]
# 时间嵌入
time_embed = self.time_embedding(flow_time_step) # 形状:[1, 256]
time_mlp = self.time_mlp(time_embed) # 形状:[1, 4608]
# 6. DiT 块(假设如论文中所述有 36 层)
dit_output = self.process_dit_blocks(
attention_output, # 形状:[1, 250, 4608]
text_proj, # 形状:[1, 512, 4608]
time_mlp # 形状:[1, 4608]
) # 输出形状:[1, 250, 4608]
# 7. 流输出
# 投影回音频潜在维度
predicted_velocity = self.flow_proj(dit_output) # 形状:[1, 250, 128]
# 8. 损失计算
true_velocity = clean_audio_latent - (1 - 1e-5) * noise # 形状:[1, 250, 128]
loss = F.mse_loss(predicted_velocity, true_velocity)
return loss
def create_audio_context(self, audio_latent):
"""
创建掩码音频上下文
参数:
audio_latent: 形状 [1, 250, 128]
"""
if random.random() < 0.5:
return torch.zeros_like(audio_latent) # 完全掩码
else:
# 部分掩码(75-100% 掩码)
mask = torch.rand(audio_latent.shape) > random.uniform(0.75, 1.0)
return audio_latent * mask.float()
def process_dit_blocks(self, features, text_cond, time_cond):
"""
通过 36 个 DiT 块处理
参数:
features: 形状 [1, 250, 4608]
text_cond: 形状 [1, 512, 4608]
time_cond: 形状 [1, 4608]
"""
x = features
for block in self.dit_blocks:
# 自注意力
x = block.self_attn(
q=x, # [1, 250, 4608]
k=x, # [1, 250, 4608]
v=x # [1, 250, 4608]
) # 输出:[1, 250, 4608]
# 与文本的交叉注意力
x = block.cross_attn(
q=x, # [1, 250, 4608]
k=text_cond, # [1, 512, 4608]
v=text_cond # [1, 512, 4608]
) # 输出:[1, 250, 4608]
# 时间调制(缩放和偏移)
scale, shift = block.time_mlp(time_cond) # 每个:[1, 4608]
x = x * scale.unsqueeze(1) + shift.unsqueeze(1)
# MLP(根据论文扩展 4 倍)
x = block.mlp(x) # 输入/输出:[1, 250, 4608]
return x解释
假设我们有一个包含音频、视频和音频描述的数据样本来训练模型。我们在 Movie Video Gen 博客中学习了如何将视频表示为向量形式。那么如何将音频表示为向量形式呢?
模拟音频是空气中的连续压力波。它通过采样转换为数字音频。44KHz 的采样率意味着每秒钟的音频被采样 44,000 次。以下是一个大致概述。
模拟到数字转换:
连续波 → 采样 → 离散值
示例(44.1kHz 采样):
1 秒音频 = 44,100 次测量
每次测量 = 振幅值(-1 到 1)音频可以是单声道或立体声。单声道音频包含一个通道,立体声包含两个通道,即左声道和右声道。
现在你应该能理解以下内容了。假设你有一个 10 秒长的 48Hz 立体声音频。以下是如何将其表示为向量形式。
# 在 48kHz 采样率下:
samples_per_second = 48000
duration_seconds = 10
total_samples = samples_per_second * duration_seconds # 480,000
# 立体声音频形状:
audio_tensor = torch.zeros(2, 480000) # 形状:[2, 480000]现在你知道了音频是如何表示为向量形式的。让我们继续逐步理解训练过程。
步骤 1:生成噪声潜在表示
他们使用了一个单独训练的 DAC_VAE(描述音频编解码器与变分自编码器)模型(另一个深度学习模型)来扩展原始音频。为什么?为了在不失去重建能力的情况下减少内存并提高计算效率。

之后,使用以下公式创建噪声音频潜在表示
# DAC-VAE 将 48kHz 降低到 25Hz:10s * 25Hz = 250 个时间帧
clean_audio_latent = self.dac_vae_encoder(audio) # 形状:[1, 250, 128]
# 从标准正态分布中采样噪声
noise = torch.randn_like(clean_audio_latent) # 形状:[1, 250, 128]
# 在时间步长 t 处创建噪声潜在表示
noised_latent = (flow_time_step * clean_audio_latent +
(1 - (1 - 1e-5) * flow_time_step) * noise) # 形状:[1, 250, 128]基本上,这是将噪声与实际音频潜在表示混合,以便模型在训练过程中学习重建音频。
步骤 2:音频上下文
类似于上述步骤,他们通过将原始视频传递给 DAC_VAE 编码器来创建音频潜在表示。
这个音频潜在表示(音频上下文)是特殊的。它被掩码并且没有与噪声混合。这意味着随机选择向量并用零向量替换。为什么这样做,因为我们已经在上一步中创建了噪声音频潜在表示?
我们希望我们的模型不仅能够生成音频,还能够根据掩码的位置填充或扩展音频。当你希望模型生成音频时,音频上下文只是一个零向量序列。当我们希望模型扩展音频时,视频中的部分音频就是音频上下文。这太棒了!一个模型可以处理所有事情。
最后,音频上下文与噪声音频潜在表示逐帧合并。
步骤 3:处理视频分支
使用从 MetaCLIP 微调的长提示 MetaCLIP 来提取视频中每一帧的 1024 维嵌入。无论视频的分辨率或帧率如何,它都通过 spatial_resize 操作转换为固定大小的向量。
这个 1024 维的视频嵌入与结果输入(音频上下文 + 噪声音频潜在表示)逐帧混合,而不是按时间混合。想知道为什么吗?
# 原始视频:30 FPS
video_frames = [frame1, frame2, ..., frame300] # 10 秒 * 30 FPS = 300 帧
# 使用长提示 MetaCLIP 提取特征
frame_featuresFluxAI 中文
© 2026. All Rights Reserved