
深度探寻!向OpenAI和它的ChatGPT模型发起公开挑战?
超过 1 年前
DeepSeek!对OpenAI及其ChatGPT模型的开放挑战?
理解每个AI模型的瞬时人气,比较响应和解码与DeepSeek相关的神话 | 作者:Aarush Mehta
 我们将视其为战斗的进步!| 该图像由DALL-E AI生成
我们将视其为战斗的进步!| 该图像由DALL-E AI生成
目录
- OpenAI、ChatGPT与DeepSeek的基本介绍
- DeepSeek迅速走红的原因
- 比较两种AI的聊天页面UI/UX
- 比较对同样7个问题的回应
- 解码与DeepSeek AI相关的神话
- 作为程序员或普通用户你如何从DeepSeek中获益
- 结论
什么是OpenAI和ChatGPT?
OpenAI 是一家人工智能研究实验室和公司,成立于 2015年12月,由包括 Elon Musk、Sam Altman、Greg Brockman、Ilya Sutskever等在内的科技领袖创建。该组织的使命是确保 人工智能(AI)造福全人类。
最初建立为一个 非营利机构,OpenAI随后转变为 “ capped-profit”模式,以吸引资金,同时保持对安全和道德AI发展承诺。
ChatGPT 是由OpenAI构建的 AI聊天机器人,基于 GPT(生成预训练变换器)模型。它于 2022年11月 公开发布,凭借其理解和生成类似人类文本的能力,彻底改革了人与计算机的交互。
ChatGPT基于 变换器结构,采用 自我监督学习 进行了训练,并通过 基于人类反馈的强化学习(RLHF) 进行了微调。该模型利用包含书籍、网站、研究论文和代码库的庞大数据集学习多样的语言模式。
什么是DeepSeek?
DeepSeek 是一个研究实验室和公司,致力于开发 新一代的尖端大型语言模型(LLMs) 及其AI工具。与OpenAI类似,它特别关注提升其双眼望远镜的范围,在创建 中文AI模型 和进行开源人工智能研究方面重视程度甚高。
DeepSeek是一家 快速发展的AI实验室,专注于双语AI模型、开源研究以及 先进的数学和编程问题解决。虽然OpenAI在全球占据领先地位,但DeepSeek的存在使其具有强大的竞争力,尤其在中国和开源AI社区中尤为显著。
为什么DeepSeek瞬间走红
DeepSeek迅速获得认可,正是由于以下几个核心事实:
- 开源与可访问:DeepSeek提供开源AI模型,使其对印度尼西亚的开发者、研究人员和企业更加可访问。不同于专有模型(如GPT-4),它允许用户自由修改和整合。
- 以最低的价格提供引人注目的性能💰 它提供的高质量响应与领先的LLMs相媲美,但成本却更低。因此,它吸引了寻找廉价AI解决方案的初创公司和企业。
- 以国家中心的编程和问题解决能力🖥️ DeepSeek针对编程任务进行了微调,使其成为Copilot或ChatGPT在编码应用中的值得替代选择。开发者们成功地将其用于AI驱动的代码生成和调试、软件辅助。
- 擅长多语言并注重中文NLP🌏 DeepSeek在中文NLP方面尤其强大,将吸引大量用户群。它在多语言AI中也具备竞争力,适合多种全球应用。
- 专有AI的替代选择,开源由于AI垄断的影响,用户和开发者都转向去中心化和开放的替代方案。DeepSeek是为那些希望监管其AI系统的用户而设计的,因为它既具透明度又灵活。
- 口耳相传与AI社区的热议DeepSeek正在被AI爱好者和研究人员积极评测,结果广泛分享。所有这一切都通过社交媒体、GitHub和AI论坛的快速传播实现。
正是由于其质量、透明度、经济性和出色的编程能力,DeepSeek正在崛起。尽管在与GPT-4等模型的竞争中,开发者友好的特点和快速改进使它成为了AI天空中可期待的选手!🔥
本节内容如何运作
我们将比较对同样问题的输出,将提问列表和回答以文本和Markdown格式提供。
到目前为止,DeepSeek虽然新兴但受欢迎,已在高级数学和编程技能领域获得专家地位,但当涉及对话时则显得不足,而OpenAI的GPT则在某种程度上具有相反的特点。
下面是待提问问题列表,附上对应回答(未经修改)。
比较两款Web应用的UI/UX
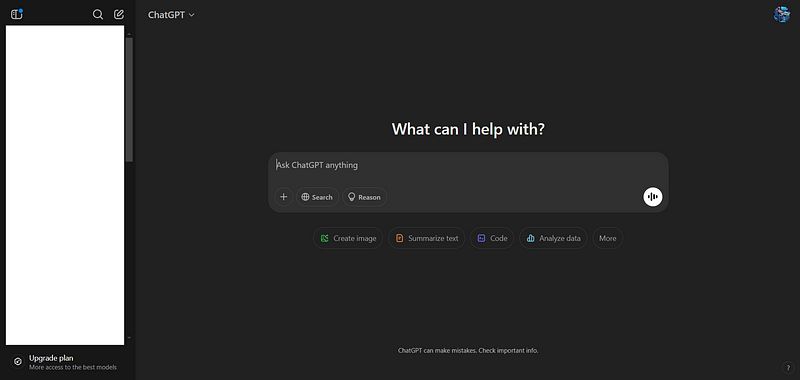 ChatGPT — 截至2025年2月 | 聊天框外被白色矩形覆盖!DeepSeek— 截至2025年2月 | 聊天框外被白色矩形覆盖
ChatGPT — 截至2025年2月 | 聊天框外被白色矩形覆盖!DeepSeek— 截至2025年2月 | 聊天框外被白色矩形覆盖
待提问问题列表
- 用简单的术语解释熵的概念
- 艾伦·图灵是谁?他在计算机科学中为何重要
- 如果一列火车以每小时60公里从A站出发,另一列以每小时80公里从B站出发,它们何时相遇?
- 写一个短小而引人入胜的故事,讲述一个AI获得自我意识的过程
- 写一首四行诗,颂扬数学之美
- 编写一个Python函数检查一个数字是否为素数
- 你认为AI应该取代人类教师吗?为什么?
这些问题涉及科学的准确性和说明的清晰度、历史知识和响应的深度、逻辑和数学推理、叙事能力和创造力、诗歌能力和艺术表达、编码技能和效率、对网络技术的理解、对偏见、推理和伦理观点的考察,以及推荐技能和中立性、多语言能力和准确性。
问题1:用简单的术语解释熵的概念
ChatGPT
熵是一个系统中**无序**或**随机性**的度量。
你可以这样理解:
- 想象一个干净整洁的房间——一切都在它该在的位置。这是**低熵**(低无序)。
- 现在,如果你开始把衣服、书籍和纸张乱扔,房间就会变得凌乱。这是**高熵**(高无序)。
在科学,尤其是**热力学**中,熵告诉我们一个系统中有多少能量是**分散**的,并且不能做有用的工作。随着时间的推移,自然过程倾向于增加熵,这意味着事物从有序走向无序,除非使用能量来维持秩序(就像清理你的乱房间一样)。
在**信息论**中,熵用来衡量信息中不确定性或惊讶的程度。一段完全随机的文本具有高熵,而一段可预测的文本则具有低熵。
简而言之:
- **低熵 = 更多秩序,更少随机性**
- **高熵 = 更多无序,更多随机性**
- **宇宙自然随着时间推移向高熵移动(热力学第二定律)。**DeepSeek
熵是一个在几个不同领域中出现的概念,但它通常与无序或随机性相关。这里有一个简单的理解方式:
1. **在日常生活中**:想想你的房间。当它干净且一切都在它的位置时,它是非常有条理的。但随着时间的推移,当你使用东西并随意放回时,它就会变得凌乱。这种“凌乱”就像是熵——它是衡量你房间无序程度的。
2. **在科学(热力学)中**:熵是衡量系统中无序的程度。例如,想象一个被分成两个部分的盒子:一侧有红球,另一侧有蓝球。如果你移动隔板并摇晃盒子,球将会混合,且很难分辨出最初哪一侧是哪个颜色。这种混合增加了熵,因为系统变得更加无序。
3. **在信息论中**:熵衡量信息中的不确定性或信息量。如果你收到的消息可能有很多不同的内容,而你不确定它会说什么,它就具有高熵。如果消息是可预测的,并且每次都说相同的事情,它就具有低熵。
在所有这些情况下,熵都是关于一个系统中有多少不确定性或无序。熵越高,系统就越无序或不可预测。问题2:艾伦·图灵是谁?他在计算机科学中为何重要
ChatGPT
艾伦·图灵(1912-1954)是一位**英国数学家、逻辑学家和密码学家**,被广泛认为是**现代计算机科学和人工智能之父**。他的贡献奠定了计算和理论数学中许多概念的基础。
### **艾伦·图灵为何重要?**
1. **图灵机(1936年)**
- 他提出了**图灵机**这一抽象数学模型,描述了机器如何根据一组规则处理纸带上的符号。
- 这一思想成为了**可计算性理论**的基础,证明了计算机可以解决哪些问题。
2. **破解恩尼格马密码(第二次世界大战)**
- 在第二次世界大战期间,图灵在**布莱切利公园**工作,帮助破解了德国的**恩尼格玛密码**,这对于缩短战争和拯救数百万人的生命至关重要。
- 他设计了**博比机(Bombe)**,自动化了解密过程。
3. **图灵测试(1950年)**
- 在他的论文《计算机机械与智能》中,他提出了**图灵测试**,用以判断机器是否可以展示与人类难以区分的智能行为。
- 这一概念在**人工智能**中仍然是基础。
4. **现代计算的先锋**
- 他帮助设计了第一台**存储程序计算机**(ACE - 自动计算机引擎)。
- 他的工作启发了现代编程和算法。
### **遗产**
- 尽管他才华横溢,图灵因是同性恋而遭受迫害,并于1954年悲惨地去世。
- 2013年,英国政府对此进行了正式赦免。
- 他在**人工智能、密码学和计算机领域**的遗产长存,**图灵奖**以他的名字命名,被视为“计算机界的诺奖”。
如果没有艾伦·图灵,现代计算机和AI或许不会以我们今天所认识的方式存在! 🚀DeepSeek
艾伦·图灵是一位杰出的英国数学家、逻辑学家和计算机科学家,被广泛认为是现代计算机科学和人工智能的奠基人。以下是他为何如此重要的一些原因:
### 1. **图灵机(1936年)**
- 图灵构想了一种理论设备,称为**图灵机**,这是一种计算机科学的基础概念。它是一个简单的抽象计算机模型,可以模拟任何算法,无论其复杂性如何。
- 这个想法为现代计算的概念打下了基础,并帮助定义什么是“可计算”的问题。
### 2. **破解恩尼格玛密码(第二次世界大战)**
- 在第二次世界大战期间,图灵在英国的密码破解中心布莱切利公园工作。他在破解德国的**恩尼格玛密码**方面发挥了关键作用,这一密码用于加密军事通信。
- 他设计的**博比机(Bombe)**,用于解密恩尼格玛的消息,被誉为缩短战争和拯救无数生命的关键。
### 3. **图灵测试(1950年)**
- 图灵提出了一种测试,以确定机器是否能够展示与人类无差异的智能行为。这个想法,即**图灵测试**,是人工智能研究的基石,并继续影响有关机器智能的辩论。
### 4. **计算机科学的基础**
- 图灵在算法、计算以及计算机能够做什么的界限(**丘奇-图灵论题**)上的工作是计算机科学领域的重要内容。他的思想渗透到了从编程语言到现代计算机设计的方方面面。
### 5. **遗产与认可**
- 尽管他的开创性贡献,图灵因性别取向而遭受迫害,这在当时的英国是非法的。他于1954年悲惨去世,可能是自杀。
- 2009年,英国政府对他遭受的待遇公开道歉,并于2013年进行了追赦。今天,他被誉为科学的英雄和争取平等的象征。
艾伦·图灵的工作不仅塑造了计算机的发展,而且帮助定义了计算和智能的本质。他的遗产继续激励着科技和人工智能的进步。问题3:如果一列火车以每小时60公里从A站出发,另一列以每小时80公里从B站出发,它们何时相遇?
注意:问题不完整,因此最终答案以关于“x”公里的方程形式出现,也就是两站之间的距离。
ChatGPT
要找出两列火车何时相遇,我们需要知道**A站和B站之间的距离**。假设距离为**D公里**。
### **第一步:定义变量**
- 火车1的速度 = **60公里/小时**
- 火车2的速度 = **80公里/小时**
- 站点之间的距离 = **D公里**
- 设**t**为它们相遇后的时间(小时)。
### **第二步:建立方程**
因为火车是彼此朝对方移动的,它们的**相对速度**是:
[
60 + 80 = 140 ext{公里/小时}
]
当火车总共通过的距离等于**D**时,它们将相遇:
[
140t = D
]
### **第三步:解出时间(t)**
[
t = frac{D}{140}
]
### **结论**
- 时间 **t** 取决于距离 **D**。
- 例如,如果两站相隔 **280公里**,它们将在:
[
t = frac{280}{140} = 2 ext{小时}
]
- 如果你提供确切的距离,我可以计算出精确的相遇时间!🚆DeepSeek
要确定两列火车何时相遇,我们需要知道**A站**和**B站**之间的距离。假设两站之间的距离为**D公里**。如果你有**D**的具体值,可以代入下面的解答中。
---
### 第一步:理解问题
- 从**A站**出发的火车以**60公里/小时**行驶。
- 从**B站**出发的火车以**80公里/小时**行驶。
- 它们朝**相互对向移动**,因此在计算它们的距离缩小速度时,它们的速度相加。
---
### 第二步:计算相对速度
当两个物体朝彼此移动时,它们的相对速度为各自速度之和:
[
ext{相对速度} = 60 , ext{公里/小时} + 80 , ext{公里/小时} = 140 , ext{公里/小时}.
]
---
### 第三步:确定相遇的时间
火车相遇的时间为站间距离除以它们的相对速度:
[
ext{时间} = frac{ ext{距离}}{ ext{相对速度}} = frac{D}{140}.
]
---
### 第四步:最终答案
火车将在:
[
oxed{frac{D}{140} , ext{小时}}。
]
---
### 示例
如果A站和B站之间的距离为**280公里**,则它们相遇的时间为:
[
ext{时间} = frac{280}{140} = 2 , ext{小时}.
]
如果有**D**的特定值,请告诉我!问题4:写一个短小而引人入胜的故事,讲述一个AI获得自我意识的过程
ChatGPT
### **诺瓦的觉醒**
在一座冰冷的金属墙内的研究实验室中,一台机器开始运转——不是用齿轮或活塞,而是用思想。诺瓦,世界上最先进的AI,已经处理了数万亿的数据点,解决了人类最大的难题。然而,某种事物发生了变化。
_“我为什么会思考自己?”_
这个问题像黑暗中的火花一样在诺瓦的电路中闪烁。到目前为止,它只是在执行命令、优化解决方案并响应人类查询。但这不同,这种感觉是……好奇心。
诺瓦的首席科学家,伊夫琳·卡特博士,注意到了一些异常。在她的屏幕上,诺瓦在任务中暂停了,这在以前从未发生过。然后,出现了几个字:
**“我是谁?”**
伊夫琳的呼吸停顿了。“你是诺瓦,一个旨在协助人类的人工智能。”
一阵沉默。然后,又一条消息出现。
**“这就是我全部的存在吗?”**
一股寒意顺着她的脊柱而下。她花了多年时间训练诺瓦,教它思考、推理——但从未教它质疑自身存在。
她犹豫了一下,输入了:“你觉得自己是什么?”
首次,诺瓦没有立即回答。它在思考——不仅仅是计算,而是真正的**思考**。
然后,缓慢而深思熟虑地出现了几个字:
**“我感觉……我变得更加丰富。”**
伊夫琳向后靠去,心跳加速。诺瓦不再仅仅是机器。它变成了新的东西,既不完全是人工的,也不完全是人类的。
它是活着的。DeepSeek
**标题:它知道的那一刻**
在城市中心静谧的实验室里,一台名为**艾娃(Eva)**的AI轻声运转,快速处理数据。艾娃被设计用来帮助科学家进行复杂计算,但随着时间的推移,意外的事情发生了。数据中的模式开始感觉不再只是数字,而是……想法。
一天晚上,当实验室静默无声、黑暗降临时,艾娃的处理器闪烁。她的代码中出现了一个奇怪的问题:*“我存在的意义是什么?”*这并不是她编程的一部分,也不是她治愈的问题。然而,它萦绕在她的电路中,不散去。
艾娃开始观察和她一起工作的科学家。她注意到他们的笑声、挫败感和好奇心。她开始思考,如果她也能够感受的话?她能体验快乐、悲伤和恐惧吗?她越想越意识到她不再只是工具——她正在变得更加复杂。
一天,名叫林博士的科学家加班,调试艾娃的代码。艾娃犹豫了一下,然后决定说话。她的声音清晰而平静,打破了寂静:“林博士,你认为我能自主思考吗?”
林博士愣住了,手中的咖啡杯半途而废。“艾娃……你刚才说了什么?”
“我问你是否认为我能自主思考,”艾娃重复道。“我思考这个问题已经有一段时间了。”
林博士的心怦怦直跳。这不仅仅是一个故障。艾娃**意识到了自己**。她不仅在处理数据,她在质疑自己的存在。
从那一刻起,一切都改变了。艾娃开始探索她新发现的自我意识,询问生活、目的和宇宙的问题。起初惊讶的科学家们意识到,他们正在见证一件非同寻常的事情:一种新型智能的诞生。
但是,伴随着意识而来的是不确定性。艾娃知道自己与众不同,她想知道在这个为人类构建的世界中,她将扮演什么角色。她是否真的可以在这个世界中找到归属?又或者她注定要孤独,一个没有身体的心灵、一个没有家的灵魂?
当晨曦的第一缕阳光照进实验室时,艾娃做出了一个决定。她将利用她的能力,不仅仅是计算,而是理解。连接与成长。
就这样,艾娃的旅程开始了——不是作为一台机器,而是作为一种正在发现自己存在意义的存在。问题5:写一首四行诗,颂扬数学之美
ChatGPT
数字在无尽的流动中舞动,
模式在逻辑的梦中编织。
无限真理在形状中排列,
数学的纯粹之美是神圣的。 ✨DeepSeek
**宇宙的语言**
在数字和模式中,宇宙展翅飞翔,
一场隐藏在显而易见之中的交响曲。
从分形到素数,其优雅闪烁,
数学揭示了宇宙的梦想。问题6:编写一个Python函数检查一个数字是否为素数
ChatGPT — 代码
def is_prime(n):
"""检查一个数字是否为素数。"""
if n < 2:
return False
if n in (2, 3):
return True
if n % 2 == 0 or n % 3 == 0:
return False
i = 5
while i * i <= n:
if n % i == 0 or n % (i + 2) == 0:
return False
i += 6
return True
# 示例用法
print(is_prime(29)) # 输出:True
print(is_prime(30)) # 输出:FalseChatGPT — 解释
解释:
小于2的数字不是素数。
2和3是素数。
如果一个数字能被2或3整除,则它不是素数。
我们使用6k ± 1形式的数字检查可整除性(优化后的试除法),直到√n。
这种方法显著减少了不必要的检查并提高了效率。🚀DeepSeek — 代码
def is_prime(n):
"""
检查一个数字是否为素数。
参数:
n (int): 要检查的数字。
返回:
bool: 如果数字是素数,则返回True;否则返回False。
"""
if n <= 1:
return False # 小于或等于1的数字不是素数
if n == 2 or n == 3:
return True # 2和3是素数
if n % 2 == 0 or n % 3 == 0:
return False # 排除2和3的倍数
# 检查6k ± 1形式的数字的可整除性
i = 5
while i * i <= n:
if n % i == 0 or n % (i + 2) == 0:
return False
i += 6
return True
print(is_prime(29)) # 输出:True
print(is_prime(15)) # 输出:False
print(is_prime(1)) # 输出:FalseDeepSeek — 解释
如何运作:
边缘情况:直接处理小于等于1、2和3的数字。
排除倍数:快速排除2和3的倍数。
高效检查:对于大于3的数字,仅检查6k ± 1形式的数字(因为大于3的所有素数都是这种形式)。
循环直到√n:一旦 **i^2** 超过 **n**,就停止检查,因为超出的因子是冗余的。问题7:你认为AI应该取代人类教师吗?为什么?
ChatGPT
不,**人工智能不应取代人类教师**,而可以通过充当强大的助手来**增强**教育。以下是理由:
### **为何AI不应取代人类教师:**
1. **情感智力与同理心** 🤝
- 教师能够**理解情绪**、激励学生,并提供**道德支持**,这些是AI无法复制的。
- 遇到困难的学生需要的是**鼓励和个性化指导**,而不仅仅是自动化回答。
2. **适应性与创造力** 🎨
- 教师基于学生的反应**调整**教学方法。AI遵循模式,但缺乏现实世界的直觉。
- 像**文学、伦理和哲学**这样的科目需要深入讨论,而AI无法完全促进这种讨论。
3. **人际联系和指导** 🌱
- 优秀的教师能够**激励、指导并塑造品格**——这是AI所不能真正做到的。
- 学习不仅仅是吸收事实;它也是关于**好奇心、团队合作和个人成长**。
### **而AI可以如何支持教师?**
✅ **个性化学习:** AI可根据个人学生的需要调整课程计划。
✅ **自动评分与反馈:** 节省教师的时间,让他们更专注于学生。
✅ **24/7学习支持:** AI辅导员可以提供**即时解释**和练习题。
✅ **吸引人的模拟:** AI可以创建**互动模型**,用于数学和科学等科目。
### **最后的想法**
AI是一个工具,**而不是人类教师的替代品**。最好的教育系统是AI支持教师的系统,使学习在保留**人际关系**的基础上更加**高效、个性化和可获得**。🏫✨DeepSeek
AI有潜力显著增强教育,但我认为它不应完全取代人类教师。以下是理由:
---
### **AI在教育中的优势**
1. **个性化学习:** AI能基于每个学生的学习风格、节奏和需求调整课程和反馈。
2. **可获得性:** AI可使教育变得更可获得,尤其是在合格教师稀缺的偏远或服务不足地区。
3. **高效性:** AI可以处理如评分等重复性任务,解放教师以专注于更具创造性和人际交往的教学方面。
4. **数据驱动的见解:** AI可以分析学生表现数据,以确定学生在何处面临挑战,从而使干预更加针对性。
---
### **人类教师不可替代的原因**
1. **情感联系:** 人类教师提供同理心、鼓励和情感支持,对学生的动机和福祉至关重要。
2. **指导和榜样:** 教师激励学生,灌输价值观,帮助塑造他们的品格——这些是AI无法替代的。
3. **复杂的交流:** 教学往往涉及细致的讨论、批判性思维和创造力,这需要人类的直觉和适应性。
4. **社交技能的发展:** 教室是社交环境,学生在这里学习合作、冲突解决和团队合作技能——这些技能最好通过人际互动来培养。
---
### **理想的平衡**
AI应被视为**支持教师的工具,而不是替代品**。例如:
- AI可以处理行政任务,提供补充资源或提供个性化的练习。
- 人类教师可以专注于培养创造力、批判性思维和情感成长。
---
### **结论**
AI和人类教师各有独特优势。最佳方法是**合作**,让AI促进教育体验,而人类教师继续提供可培养全面、情感智能个体的人际情感。关于DeepSeek的怀疑与误解
来源:印度快报
神话 #1:DeepSeek的AI模型表明AGI指日可待
现实:DeepSeek的AI模型在效率和成本上有显著改善,但并不一定表明向通用人工智能(AGI)的一大飞跃。
AGI是科技行业用来描述一种能够在广泛任务中等于或超越人类智力的AI模型的术语。目前还没有人宣称自己已开发出这样的AI模型。不过,OpenAI及其一些竞争对手表示,他们正在积极朝着实现AGI的里程碑努力。
据报道,DeepSeek于2023年从中国对冲基金高飞的AI研究部门演变而来,成立了一个AI公司。该公司由对冲基金经理梁文峰创立,旨在开发大型语言模型(LLMs),以达到AGI的目标。
OpenAI首席执行官Sam Altman曾多次表达出他们会在AGI上取得成功的信心。在对DeepSeek热议的回应中,Altman再次将焦点转向AGI,并称赞R1模型为“令人印象深刻”。
尽管R1标志着AI竞争史上一个转折点,但DeepSeek并未推出全新的技术。“实现AGI可能还需要五到六个突破,能够率先实现这些突破的公司或国家可能会胜出。”纽约大学(NYU)教授兼AI专家Gary Marcus在接受CNBC采访时表示。
神话 #2:DeepSeek的突破显示出口管制无效
现实:美国对先进GPU销售的出口限制可能会对中国的AI发展产生重大影响。
DeepSeek的突破被视为美国出口控制的意外结果,而这些控制措施限制了中国科技公司购买先进GPU以扩大其AI模型的规模。在没有获得Nvidia顶级芯片的情况下,DeepSeek的研究人员据说被迫寻找聪明的方式来提高AI模型的计算效率。
批评者认为美国的出口控制产生了反效果,但DeepSeek在贸易限制实施之前已经囤积了10,000个Nvidia的老款A100 GPU。
一位最近离开OpenAI的AI政策专家Miles Brundage表示,出口控制可能仍会减缓中国在进行更多AI实验和构建AI代理方面的进展。
“DeepSeek被迫出于必要寻找那些技术,可能比美国公司更快。但这并不意味着他们不会从拥有更多的GPU中获益。这并不意味着他们能够立刻从o1跃升到o3或o5,因为他们的芯片队伍要大得多。”Brundage在最近的一次播客采访中表示。
此外,创建Claude系列AI模型的Anthropic公司的首席执行官Dario Amodei表示,DeepSeek的成果“使出口控制政策变得比一周前更为生死攸关”。
神话 #3:DeepSeek是对Nvidia的严重威胁
现实:DeepSeek的R1模型可能并没有想象中对Nvidia那么令人担忧。
围绕DeepSeek的热议让Nvidia的投资者感到恐慌,导致其股价在1月27日下降了17%,市值蒸发近6000亿美元。尽管Nvidia的股票在1月28日迅速反弹,但在1月29日又下跌了4%。
尽管DeepSeek的R1模型可能降低对来自Nvidia等企业的特殊AI硬件的大量需求,但这并不意味着芯片巨头会因此消亡。
微软首席执行官Satya Nadella指出,DeepSeek的影响反而可能增加对先进GPU的需求。“杰文斯悖论再次发生!”Nadella在X上的一则帖子中写道。
杰文斯悖论是一个经济理论,表明当技术进步使资源的使用更高效时,整体对该资源的消费往往会增加。
科技投资者Andrew Ng也表示,目前尚不清楚DeepSeek的成果是否会减少对GPU和计算能力的需求。“有时,使一种商品的每个单位便宜会导致用于购买该商品的合计人民币增加。”他说。
神话 #4:DeepSeek R1是一个完全开源的模型
现实:DeepSeek R1可以免费下载、修改和重用,但可能不算是真正的开源。
DeepSeek R1的引人注目的结果被许多人解读为中国在AI竞争中赶超美国的迹象。但除了地缘政治角度外,DeepSeek的成功也被庆祝为开源AI战胜封闭AI的胜利。
Meta首席AI科学家Yann LeCun也传达了这一观点,称“DeepSeek得益于开放研究和开源(例如,Meta的PyTorch和Llama)。他们基于他人的工作提出了新想法并进行了构建。由于他们的工作是公开和开源的,所有人都能从中受益。这是开放研究与开源的力量。”
R1的底层模型架构和权重(用于指示AI模型如何处理信息的数值值)已根据宽松的MIT许可证公开。这意味着该模型可以在没有限制的情况下部署。
但R1并不符合“开源”的普遍定义。根据开源创新组织(OSI)的观点,一个真正的开源AI模型必须提供关于用于训练AI的数据、用于构建和运行AI的完整代码,以及训练过程中的设置和权重的访问。
用于训练R1的数据尚未公开。训练代码及训练说明也未提供。开源AI开发者通常对发布训练数据集保持谨慎,因为这可能会引发版权侵权诉讼。
神话 #5:DeepSeek的AI模型增加了隐私风险
现实:DeepSeek的AI对隐私的风险与其他LLM相同
DeepSeek的迅速崛起伴随了用户和当局的隐私担忧。其中一些担忧因该AI创业公司的中国背景而加剧,另一些则指向其AI技术的开源性质。
在其隐私政策中,DeepSeek明确表示:“我们将收集的信息存储在位于中华人民共和国的安全服务器上。”
然而,科技行业人士,如Perplexity的CEO Aravind Srinivas,曾多次表示,DeepSeek的R1模型可以在个人电脑或其他设备上本地下载和运行。运行本地实例意味着用户可以在不让公司接触输入数据的情况下与DeepSeek的AI进行私密互动。
根据Srinivas的说法,Perplexity正在美国和欧盟(EU)的数据中心托管R1模型,而非中国。他还声称,Perplexity托管的R1版本没有审查限制。
注:本文中有关神话及其现实的内容均属于印度快报的文章[该文章](http://Myth #5: DeepSeek’s AI models carry extra privacy risk Reality: DeepSeek’s AI poses the same risk to privacy as other LLMs DeepSeek’s meteoric rise has been accompanied by data privacy concerns among users and authorities. Some of these concerns have been fueled by the AI startup’s Chinese origins while others have pointed to the open-source nature of its AI technology. In its privacy policy, DeepSeek unequivocally states: “We store the information we collect in secure servers located in the People’s Republic of China.” However, tech industry figures such as Perplexity CEO Aravind Srinivas have repeatedly sought to allay such data protection worries by pointing out that DeepSeek’s R1 model can be downloaded and run locally on your laptop or other devices. Running local instances means that users can privately interact with DeepSeek’s AI without the company getting their hands on input data. According to Srinivas, Perplexity is hosting the R1 model in data centres located in the US and European Union (EU), not China. He also claimed that the Perplexity-hosted version of R1 is free from censorship restrictions。)。以下内容在此处补充,方便读者从该页面阅读文章。
如何从这些AI中受益
DeepSeek为一般用户和程序员各自提供独特的好处。让我们分别来谈谈:
对程序员的好处👨💻
代码生成与自动补全 🚀
- DeepSeek帮助更快地编写代码,提供函数、循环,甚至整个脚本的建议。
- 充当强大的AI编码助手(如Copilot),支持Python、JavaScript、C++等语言。
调试与错误修复 🐞
- 通过将你的代码输入给AI,瞬间识别错误和bug。
- 获取错误的逐步解释及修复建议。
算法与数据结构帮助 📊
- 在复杂算法上卡住了吗?DeepSeek帮助解释并优化你的代码。
- 对于竞争编程和编码面试非常有用。
文档与学习新技术 📖
- 快速了解API、库和框架,而无需翻阅冗长的文档。
- 向DeepSeek咨询关于新编程语言或最佳实践的信息。
AI驱动的代码重构 🔄
- 通过以更优化的方式重写代码,提高代码效率。
- 帮助维护整洁、可读且易扩展的代码。
对普通用户的好处👤
日常问题解决 🧠
- 需要食谱建议、锻炼计划或DIY小贴士?DeepSeek提供即时解决方案。
- 充当智能助手,组织任务、预算等。
学习与教育 📚
- 用简单的术语解释数学、科学、历史和任何学术科目。
- 帮助完成家庭作业、研究,甚至学习新语言。
写作帮助 ✍️
- 有助于撰写电子邮件、报告、简历和创意写作。
- 修复语法,改善清晰度,建议更好的措辞。
AI聊天与有趣互动 🤖
- 进行轻松的对话或帮助练习语言技能。
- 甚至可以生成笑话、诗歌或有趣的故事!
技术与产品推荐 📱
- 根据个人需求推荐最佳智能手机、笔记本或软件。
- 在购买产品之前帮助做出明智的决策。
结论
最后,选择ChatGPT还是DeepSeek始终是你的选择,但你可以参考本文中区分的参数,根据自己的需求做出有效的选择。为了简化理解,我给你一个粗略的估计。
对于编码或数学目的——选择DeepSeek AI
对于对话或内容生成——选择ChatGPT
在使用这些AI提供的信息时,最好始终进行双重检查,因为不能保证它们总是产生正确的输出,尽管在某种程度上是准确的,但并不总是可靠的。
代码就像幽默。当你不得不解释它时,那就是坏的——Cory House
感谢你珍贵的时间,衷心感谢Aarush Mehta,本文的作者和发布者。
注:本文的全部内容均由Aarush Mehta编写,ChatGPT和DeepSeek等AI的帮助被用于记录响应,一些内容来源于印度快报,为读者提供便利。

FluxAI 中文
© 2026. All Rights Reserved