
完全微调 FLUX 的结果明显优于 LoRA 训练,这也是预期之中的,过拟合和……
将近 2 年前
配置和完整实验
- 完整的配置和网格文件在这里共享: https://www.patreon.com/posts/kohya-flux-fine-112099700




细节
- 我仍在严格测试不同的超参数,并比较每个参数的影响,以找到最佳工作流程
- 到目前为止,已经完成了16次不同的完整训练,目前还在完成8次
- 我正在使用我那15张图像的数据集进行实验(第4张图)
- 我已经证明,当我使用更好的数据集时,效果会好很多,并且能够完美生成表情
- 这里是一个示例案例:https://www.reddit.com/r/FluxAI/comments/1ffz9uc/tried_expressions_with_flux_lora_training_with_my/
结论
- 当分析结果时,微调的过拟合程度较低,更加通用且质量更好
- 在前两张图中,能够更好地改变发色和添加胡须,意味着过拟合程度较低
- 在第三张图中,你会注意到盔甲的效果更好,因此过拟合程度较低
- 我注意到环境和服装的过拟合程度较低,质量更好
缺点
- Kohya 仍然不支持 FP8 训练,因此 24 GB 的 GPU 速度大幅下降
- 此外,48 GB 的 GPU 必须使用融合反向传播优化,因此也会有一些速度下降
- 由于缺乏 FP8,16 GB 的 GPU 速度下降更为明显
- Clip-L 和 T5 训练仍不支持
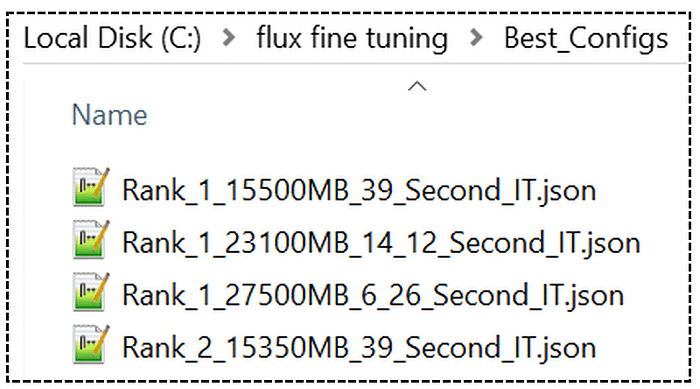
速度
- 排名 1 快速配置 — 使用 27.5 GB VRAM,6.28 秒/次(LoRA 为 4.85 秒/次)
- 排名 1 较慢配置 — 使用 23.1 GB VRAM,14.12 秒/次(LoRA 为 4.85 秒/次)
- 排名 1 最慢配置 — 使用 15.5 GB VRAM,39 秒/次(LoRA 为 6.05 秒/次)
最终信息
- 保存的检查点为 FP16,因此为 23.8 GB(未训练 Clip-L 或 T5)
- 根据 Kohya 的说法,应用的优化不会改变质量,因此目前所有配置均排名为排名 1
- 我仍在测试这些优化是否对质量有影响
- 我仍在尝试寻找改进的超参数
- 所有训练均在 1024x1024 下进行,因此降低分辨率将提高速度,减少 VRAM,但也会降低质量
- 希望当 FP8 训练到来时,我认为即使是 12 GB 的 GPU 也能以良好的速度进行全面微调
推荐阅读:






FluxAI 中文
© 2026. All Rights Reserved