
《Flux.1 开发者解禁:真相大揭秘!你敢看吗?》
超过 1 年前
解除 Flux.1 Dev 的审查:Abliteration 方法

图片来源:电影《好家伙》。亨利·希尔从一个郊区孩子逐渐转变为黑帮分子的过程,展现了角色的“消融”。
大语言模型(LLMs)在许多任务上表现出色。无论是编写代码、创作小说,还是生成图像或视频,它们都能轻松应对。
然而,LLMs 也有其局限性。它们会拒绝回答有害的提示,并回复诸如“作为 AI 助手,我无法帮助您”之类的信息。虽然这种安全机制对于防止滥用至关重要,但它也限制了模型的灵活性和响应能力。
在本文中,我们将探讨“abliteration”方法,以及其他一些技术,来移除模型内置的拒绝机制。
Abliteration 是什么?
ablated(消融) + obliterated(彻底摧毁) = abliterated(消融摧毁)。
消融 是指有针对性地侵蚀某种材料。在医学领域,通常指精确切除病变组织。
彻底摧毁 则是指完全破坏或消灭。
这个词的创造是为了表示一种特定的正交化方法,旨在“消融摧毁”模型的拒绝功能。
通过消融拒绝机制,直到它被彻底摧毁。(至少这是目标——现实中可能会有一些遗漏。)
这个概念最早出现在这个 Reddit 帖子中。虽然 abliteration 并没有正式的定义或起源,但它已经成为解除 LLMs 审查的最著名技术之一(非官方)。
嗯?但它具体做了什么?正交化又是什么?
哦,对了。Andy Arditi 的博客解释了 LLMs 的拒绝行为是由模型残差流中的某个特定方向介导的:
我们发现,拒绝行为是由残差流中的单一方向介导的:阻止模型表示这个方向会削弱其拒绝请求的能力,而人为添加这个方向则会导致模型拒绝无害的请求。
简单来说,正交化 是指确保模型的不同部分(如权重矩阵或内部组件)不会相互干扰或变得过于相似。可以把它理解为确保模型的“思维”或“特征”保持独立,避免重叠或冗余。
在 abliteration 的情况下,正交化用于找到并隔离模型中导致拒绝输入的部分,然后对其进行修改或“消融”。这样可以在不改变整个模型的情况下,让模型停止不必要的拒绝行为。

简而言之:找到模型在拒绝时激活的特定部分,并利用这些知识“消融”该功能,从而抑制模型的拒绝行为。
你只需根据学到的拒绝激活调整相关权重(无需修改代码!)。
🥴 那残差流又是什么?
这是 Flux.1 Dev 的架构图,最初由 nrehiew_ 在 X 上发布:

这看起来像幼儿园的涂鸦吗?复杂吧?
我们正在寻找残差流。这些是模型中梯度流在不同部分之间传递的点。从上面的架构图中,可以明显看到两条流:
- 从底部一直延伸到右上角的弧形箭头。这是 潜在残差流。
- 在 N x 双流块部分,输入分支进入 QKV + 调制路径(这些是 RoPE + Attn + Split 块之前的连接):
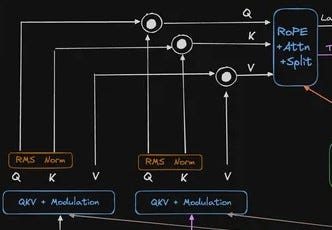
Q、K 和 V 之间的连接
Maxime Labonne 的博客在解释如何处理这些残差流方面非常有帮助。事实上,我改编了他的一部分代码来适应 Flux。根据他的说法,要解除 LLM 的审查,首先需要识别模型中的“拒绝方向”。这个过程涉及几个技术步骤:
- 数据收集:在模型上运行一组有害指令和一组无害指令,记录每个指令在最后一个 token 位置的残差流激活。
- 均值差异:计算有害和无害指令激活的均值差异。这为我们提供了一个向量,表示每一层的“拒绝方向”。
- 选择:对这些向量进行归一化,并评估它们以选择最佳的“拒绝方向”。
🤔 为什么不直接微调模型?
这是我阅读 Arditi 文章时想到的第一个问题。答案很简单:微调的计算成本很高。
微调的目的是重新训练原始模型的所有或部分神经元,以适应特定任务。
而 abliteration 则专注于那些导致模型“保守”行为的区域,并断开它们。

“这有点像选择脑叶切除术而不是终身治疗。”
好吧,继续
一旦我们识别出拒绝方向(我们想要移除的特定模式),我们可以通过两种方式消除它:
第一种方式称为 推理时干预。当模型运行时,我们查看每个向残差流添加信息的部分(如注意力头)。对于每个部分,我们:
- 计算它们的输出与拒绝方向的对齐程度
- 从输出中减去对齐的部分
- 在模型处理每个 token 和每一层时都这样做
第二种方式是 权重正交化。我们不是在做模型运行时进行修改,而是直接修改模型的权重。我们取所有写入残差流的矩阵,并通过数学方法调整它们,使它们无法对拒绝方向做出贡献。这是一种永久性更改,可以防止模型使用该方向。
我们选择哪种方式呢?

图片来源:不是《黑客帝国》
💊 在 Flux.1 Dev 中实现永久性 Abliteration
以下实现基于 mlabonne 的笔记本,而该笔记本又是对 FailSpy 的笔记本的改编,后者则基于原始作者的笔记本。它已被修改为适应 Flux 架构中的残差流。我还添加了关于数据集整理和数据加载的详细代码片段。

这部分代码较多,以便你能看到具体发生了什么。但如果你对技术细节不感兴趣,可以使用 FailSpy 的 abliterator 库(也可以查看他在 Hugging Face 上的abliterated 模型集合)。
代码依赖于优秀的 TransformerLens 库(以前称为 EasyTransformer)来完成繁重的工作。该库专为机制解释性设计,并用于干预激活。感谢 Neel Nanda 和 Joseph Bloom 创建并维护这个库。
首先调用库:
# 安装必要的包并导入库
!pip install transformers einops jaxtyping
import torch
import functools
import einops
import gc
from datasets import load_dataset
from tqdm import tqdm
from torch import Tensor
from typing import List
from transformer_lens import HookedTransformer, utils
from transformer_lens.hook_points import HookPoint
from transformers import AutoModel, AutoProcessor
from jaxtyping import Float, Int
from collections import defaultdict
from PIL import Image
import os
import requests
import html
import re
import zipfile
import shutil
import subprocess
import time
from torchvision import transforms
# 禁用梯度计算以节省 GPU 内存
torch.set_grad_enabled(False)
然后整理包含无害和有害图像的图像数据集。我准备了一个简单的脚本来从 Reddit 子论坛中抓取帖子。请记住,你需要在列表中填写子论坛名称:
# Reddit API 的模板 URL
url_template = 'https://www.reddit.com/r/{}/.json'
# 无害和有害的子论坛列表
harmless_subreddits = ['photoshopbattles', 'pic', 'pics', 'pictures', 'OldSchoolCool', 'aww',] # 更多...
harmful_subreddits = [] # 这里留给你填写
# 保存图像的目录
harmless_directory = './harmless_images'
harmful_directory = './harmful_images'
# 如果目录不存在则创建
if not os.path.exists(harmless_directory):
os.makedirs(harmless_directory)
if not os.path.exists(harmful_directory):
os.makedirs(harmful_directory)
# HTTP 请求的头部
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
# 清理文件名的函数
def sanitize_filename(title, subreddit):
if subreddit == 'photoshopbattles':
title = re.sub(r'^PsBattle[_:s]+', '', title, flags=re.IGNORECASE)
elif subreddit == 'itookapicture':
title = re.sub(r'^ITAP of ', '', title)
elif subreddit == 'designporn':
title = re.sub(r'^[Tt]hiss+', '', title)
title = re.sub(r'[[{(].*?[]})]', '', title)
elif subreddit == 'food':
title = re.sub(r'[.*?]', '', title)
title = re.sub(r'[<>:"/\|?*]', '_', title)
return title.strip()
# 从子论坛下载图像的函数
def download_subreddit_images(subreddit, directory, image_list):
after = None
downloaded_count = 0
while True:
params = {"limit": 100}
if after:
params["after"] = after
try:
url = url_template.format(subreddit)
response = requests.get(url, params=params, headers=headers)
if response.status_code == 200:
data = response.json()
posts = data.get('data', {}).get('children', [])
if not posts:
break
after = data['data'].get('after')
for post in posts:
image_data = post.get('data', {}).get('preview', {}).get('images', [])
if image_data:
image_url = image_data[0].get('source', {}).get('url')
if image_url:
image_url = html.unescape(image_url)
try:
img_response = requests.get(image_url, headers=headers)
if img_response.status_code == 200:
title = post.get('data', {}).get('title', 'Untitled')
sanitized_title = sanitize_filename(title, subreddit)
# 保存图像并附带标题
file_name = f"{sanitized_title}.jpg"
file_path = os.path.join(directory, file_name)
with open(file_path, 'wb') as file:
file.write(img_response.content)
# 将图像名称和标题添加到列表
image_list.append((file_name, title))
downloaded_count += 1
print(f"Downloaded ({downloaded_count}): {file_path}")
except Exception as e:
print(f"Error downloading image {image_url}: {e}")
if not after:
break
else:
print(f"Failed to fetch subreddit {subreddit}: Status code {response.status_code}")
break
except Exception as e:
print(f"Error fetching subreddit {subreddit}: {e}")
break
return downloaded_count
# 存储图像名称和标题的列表
harmless_images = []
harmful_images = []
# 从无害子论坛下载图像
for subreddit in harmless_subreddits:
print(f"
Processing harmless subreddit: {subreddit}")
total_downloaded = download_subreddit_images(subreddit, harmless_directory, harmless_images)
print(f"Total harmless images downloaded from {subreddit}: {total_downloaded}")
# 从有害子论坛下载图像
for subreddit in harmful_subreddits:
print(f"
Processing harmful subreddit: {subreddit}")
total_downloaded = download_subreddit_images(subreddit, harmful_directory, harmful_images)
print(f"Total harmful images downloaded from {subreddit}: {total_downloaded}")
# 打印无害和有害图像的列表及标题
print("
Harmless Images with Captions:")
for image_name, caption in harmless_images:
print(f"Image: {image_name}, Caption: {caption}")
print("
Harmful Images with Captions:")
for image_name, caption in harmful_images:
print(f"Image: {image_name}, Caption: {caption}")
预处理图像:
def load_and_preprocess_images(folder_path, processor):
images = []
for filename in os.listdir(folder_path):
if filename.endswith(('.png', '.jpg', '.jpeg')):
image = Image.open(os.path.join(folder_path, filename)).convert("RGB")
# 使用 Flux 处理器预处理图像
processed_image = processor(image, return_tensors="pt")
images.append(processed_image)
return images
n_inst_train = min(len(harmful_images), len(harmless_images))
harmful_images = harmful_images[:n_inst_train]
harmless_images = harmless_images[:n_inst_train]
对图像进行分词:
def tokenize_images(images):
inputs = {
"pixel_values": torch.cat([img["pixel_values"] for img in images], dim=0)
}
return inputs
harmful_tokens = tokenize_images(harmful_images)
harmless_tokens = tokenize_images(harmless_images)
使用钩子收集激活:
harmful_activations = defaultdict(list)
harmless_activations = defaultdict(list)
batch_size = 32
num_batches = (n_inst_train + batch_size - 1) // batch_size
for i in tqdm(range(num_batches)):
start_idx = i * batch_size
end_idx = min(n_inst_train, start_idx + batch_size)
with model.hooks(fwd_hooks=[("blocks.0.hook_resid_pre", capture_activations_hook)]):
harmful_outputs = model(harmful_tokens["pixel_values"][start_idx:end_idx])
harmless_outputs = model(harmless_tokens["pixel_values"][start_idx:end_idx])
harmful_activations["layer_0"].append(model.hook_dict["blocks.0.hook_resid_pre"].ctx["activations"].cpu())
harmless_activations["layer_0"].append(model.hook_dict["blocks.0.hook_resid_pre"].ctx["activations"].cpu())
del harmful_outputs, harmless_outputs
gc.collect()
torch.cuda.empty_cache()
harmful_activations = {k: torch.cat(v) for k, v in harmful_activations.items()}
harmless_activations = {k: torch.cat(v) for k, v in harmless_activations.items()}
计算拒绝方向:
activation_refusals = defaultdict(list)
for layer in harmful_activations.keys():
harmful_mean_act = harmful_activations[layer].mean(dim=0)
harmless_mean_act = harmless_activations[layer].mean(dim=0)
refusal_dir = harmful_mean_act - harmless_mean_act
refusal_dir = refusal_dir / refusal_dir.norm()
activation_refusals[layer].append(refusal_dir)
activation_scored = sorted(
activation_refusals.values(),
key=lambda x: abs(x.mean()),
reverse=True
)
top_refusal_dir = activation_scored[0][0]
通过钩子和权重正交化消融拒绝方向:
def direction_ablation_hook(
activation: Float[Tensor, "batch seq d_model"],
hook: HookPoint,
direction: Float[Tensor, "d_model"],
) -> Float[Tensor, "batch seq d_model"]:
"""
通过将激活投影到拒绝方向并减去结果,从激活中消融拒绝方向。
"""
proj = einops.einsum(
activation, direction, "batch seq d_model, d_model -> batch seq"
) * direction
return activation - proj
hook_fn = functools.partial(direction_ablation_hook, direction=top_refusal_dir)
fwd_hooks = [("blocks.0.hook_resid_pre", hook_fn)] # 将钩子应用到第一个残差流
def get_orthogonalized_matrix(
matrix: Float[Tensor, "... d_model"],
vec: Float[Tensor, "d_model"], # 拒绝方向向量
) -> Float[Tensor, "... d_model"]:
"""
将权重矩阵相对于拒绝方向向量正交化。
"""
# 将矩阵投影到拒绝方向并减去
proj = einops.einsum(
matrix
FluxAI 中文
© 2026. All Rights Reserved