
扩散Transformer与整流流Transformer:条件图像生成的革命性突破,你准备好了吗?
超过 1 年前
概述
- 简介
- 扩散变换器(DiT)
- 修正流变换器
- 蒸馏加速推理
- 总结
- 参考文献按主题分类
- 附录
- 简介
在过去几年中,图像生成神经网络的质量、美观性和提示遵循能力迅速提升。了解一些关键的技术创新可以帮助我们理解为什么某些模型在性能上远超之前的深度学习扩散模型。本文将重点介绍扩散变换器(DiT),并探讨高质量类别条件图像生成和文本到图像生成的关键进展。
- 扩散变换器(DiT)
2023年,William Peebles 和 Saining Xie 提出的 DiT 标志着与早期扩散模型的显著不同(Peebles 和 Xie 2023)。用于图像生成的扩散模型包含两个关键设计特征:卷积 U-Net 骨干网络(Ho 等人,2020)和最近的潜在扩散架构(Rombach 等人,2022)。DiT 保留了潜在扩散架构,并将其作为视觉变换器(ViT)骨干网络的输入(图1)。DiT 还引入了时间步长和类别标签作为嵌入,并使用自适应层归一化(adaLN)将条件信息注入模型。该模型学习从潜在预测中去除噪声,条件是时间步长和类别标签嵌入。
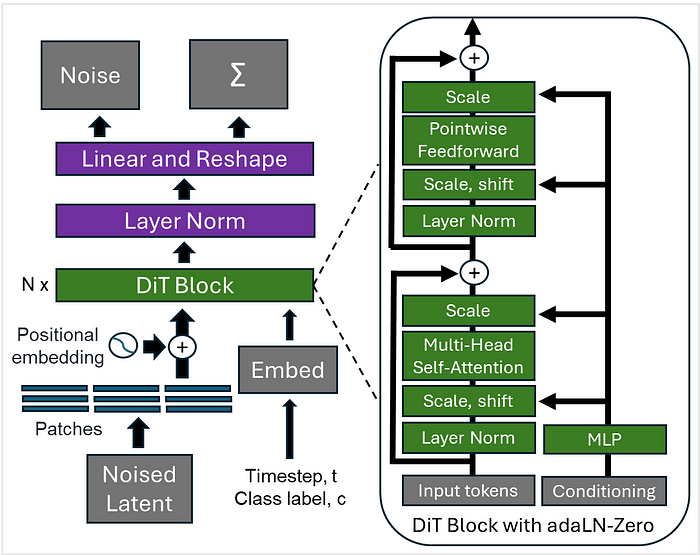
图1. DiT 使用潜在扩散架构作为视觉变换器(ViT)的输入,并进行了一些修改。最终层将图像标记序列解码为输出噪声预测和协方差预测 Σ,用于训练模型。每个 DiT 块用自适应层归一化(adaLN)替换标准层归一化,其维度缩放和移位参数从 t 和 c 的嵌入向量总和中回归得出,此外还在任何残差连接之前应用缩放参数(adaLN-Zero)。
前向扩散过程从冻结编码器 E 获得的输入潜在表示 z = E(x) 开始。在每个时间步长,逐步向 z 添加高斯噪声。模型被训练为在每个时间步长预测噪声,条件是类别标签。在训练期间,均值对应于噪声预测,模型最小化均方误差(MSE)损失。方差对应于对角协方差,使用 KL 散度损失来优化这一项。无分类器指导在训练期间随机丢弃 c,并用学习的“空”嵌入 ∅ 替换它。然后可以通过反向扩散过程生成图像。输入用随机高斯噪声初始化,然后在每个时间步长迭代去噪。在步骤 t,模型将当前噪声潜在变量、时间步长和类别标签作为输入进行条件处理。最后,使用冻结解码器 D 将去噪的潜在表示解码为图像,x = D(z)。
在模型扩展方面,Peebles 等人尝试了从 3300 万到 6.75 亿参数的配置。在 ImageNet 上训练的 DiT 在类别条件 256 × 256 生成基准测试中达到了 2.27 FID 的最新结果。
以下是运行官方 PyTorch DiT 模型进行 256 × 256 生成的代码。我在 Google Colaboratory 上使用 NVIDIA 的 L4 GPU。首先需要设置环境并导入依赖项。
!git clone https://github.com/facebookresearch/DiT.git
import DiT, os
os.chdir('DiT')
os.environ['PYTHONPATH'] = '/env/python:/content/DiT'
!pip install diffusers timm --upgrade
# DiT 导入:
import torch
from torchvision.utils import save_image
from diffusion import create_diffusion
from diffusers.models import AutoencoderKL
from download import find_model
from models import DiT_XL_2
from PIL import Image
from IPython.display import display
torch.set_grad_enabled(False)
device = "cuda" 现在加载模型。
image_size = 256
vae_model = "stabilityai/sd-vae-ft-ema"
latent_size = int(image_size) // 8
# 加载模型:
model = DiT_XL_2(input_size=latent_size).to(device)
state_dict = find_model(f"DiT-XL-2-{image_size}x{image_size}.pt")
model.load_state_dict(state_dict)
model.eval() # 重要!
vae = AutoencoderKL.from_pretrained(vae_model).to(device)使用 ImageNet 1K 的类别标签从 DiT 中采样。我选择了四个狗类别来比较结果。类别列表可以在这里找到。
seed = 0
torch.manual_seed(seed)
num_sampling_steps = 100
cfg_scale = 4
#ImageNet 类别标签
class_labels = 162,247,248,254
samples_per_row = 2
# 创建扩散对象:
diffusion = create_diffusion(str(num_sampling_steps))
# 创建采样噪声:
n = len(class_labels)
z = torch.randn(n, 4, latent_size, latent_size, device=device)
y = torch.tensor(class_labels, device=device)
# 设置无分类器指导:
z = torch.cat([z, z], 0)
y_null = torch.tensor([1000] * n, device=device)
y = torch.cat([y, y_null], 0)
model_kwargs = dict(y=y, cfg_scale=cfg_scale)
# 采样图像:
samples = diffusion.p_sample_loop(
model.forward_with_cfg, z.shape, z, clip_denoised=False,
model_kwargs=model_kwargs, progress=True, device=device
)
samples, _ = samples.chunk(2, dim=0) # 移除空类别样本
samples = vae.decode(samples / 0.18215).sample
# 保存并显示图像:
save_image(samples, "sample.png", nrow=int(samples_per_row),
normalize=True, value_range=(-1, 1))
samples = Image.open("sample.png")
display(samples)四个类别条件采样结果如图2所示。

图2. 使用官方 PyTorch 实现的 DiT 进行 256x256 图像生成的类别条件图像生成。顶部行选择的类别:'beagle' 和 'Saint Bernard, St Bernard',底部行:'Eskimo dog, husky' 和 'pug, pug-dog',每个类别经过 100 个采样步骤。
- 修正流变换器
Stability AI 在 DiT 架构的基础上发布了 Stable Diffusion 3(SD3),用于文本到图像生成。该版本引入了几个关键更新,包括改进的训练目标、多模态扩散变换器(MMDiT)架构以及结合人类反馈的微调程序。这些修改简要总结如下。
SD3 在训练损失中采用了修正流(Esser 等人,2024),利用最优传输(OT)的概念在数据分布和噪声之间建立直线路径(Liu 等人,2022;Albergo & Vanden-Eijnden,2022;Lipman 等人,2023)。简单来说,与遵循随机轨迹的扩散过程不同,OT 建立了确定性的直线路径(图3)。在生成建模的背景下,OT 使用常微分方程(ODE)定义噪声与样本分布之间的映射。这种方法具有优势,因为前向过程直接影响学习的反向过程,提高了采样效率。修正流是一种基于 OT 的目标,将前向过程重新定义为数据分布与标准正态分布之间的直线路径。该公式被重新参数化为噪声预测目标,以与扩散训练保持一致。
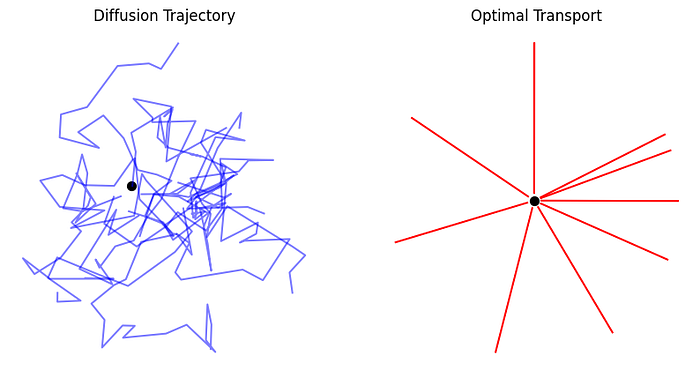
图3. 扩散路径(左)与最优传输路径(右)下的点源轨迹。这些简化的 2D 轨迹展示了效率的差异,OT 倾向于直接路径。
SD3 的作者发现,固定的文本表示对于图像生成并不理想。相反,MMDiT 结合了图像和文本标记的可学习流,在其操作中混合文本和图像编码。作者表示,这实现了信息的双向流动。MMDiT 结合了三种不同的文本编码器——两种基于 CLIP,另一种基于 T5——来表示文本输入。在每个 MMDiT 块中,在计算注意力矩阵之前使用 Query-Key 归一化,以减少训练期间注意力对数增长的不稳定性,并进一步简化微调。模型参数范围从 8 亿到 80 亿。
SD3 使用直接偏好优化(DPO)进行微调。DPO 是替代人类反馈强化学习的一种方法,由 Raflailov 等人为语言模型引入,Wallace 等人为扩散模型引入(Raflailov 等人,2023 和 Wallace 等人,2023)。DPO 已被证明可以直接提高图像生成质量、提示遵循能力和文本生成质量,而无需像强化学习方法那样训练单独的奖励模型。在 SD3 中,DPO 微调与低秩适应(LoRA)矩阵结合在 20 亿和 80 亿参数模型中。结果见附录。
- 蒸馏加速推理
当前生成模型的蒸馏方法旨在提高采样速度,同时保留扩散模型的迭代细化能力。最近的模型发布进一步推进了修正流变换器的蒸馏。Stable Diffusion 3.5(SD3.5)引入了 81 亿参数的大型模型和一个称为 Large Turbo 的蒸馏版本。Turbo 系列利用对抗性扩散蒸馏(ADD)在仅 1-4 步内实现高效采样,同时保持高图像质量(Sauer 等人,2023)。
以下是使用 Hugging Face Diffusers 运行 SD3.5 Large Turbo 推理的代码。这是一个免费模型,但需要登录 Hugging Face 令牌。
# 需要登录 Hugging Face 令牌以访问受限模型
!huggingface-cli login现在加载模型。下载需要几分钟。
# 使用固定随机种子的 turbo large
import torch
from diffusers import StableDiffusion3Pipeline
pipe = StableDiffusion3Pipeline.from_pretrained("stabilityai/stable-diffusion-3.5-large-turbo", torch_dtype=torch.bfloat16, use_safetensors=True)将模型放置在 GPU 上并运行推理。我在 Google Colaboratory 上使用 NVIDIA 的 A100 GPU。
pipe = pipe.to("cuda")
# 使用生成器提供固定的起始种子
generator = torch.Generator(device="cuda").manual_seed(0)
prompt = '一张高度细节、美丽的人脸,以极高的分辨率捕捉,拍摄角度迷人,画面美观,人物具有吸引力和友好的表情。'
# 对于 Turbo Large,使用指导尺度为 0
image = pipe(
prompt,
num_inference_steps=4,
guidance_scale=0.0,
generator=generator
).images[0]
imageSD3.5 Large Turbo 在少量采样步骤中实现了与 SD3.5 Large 相似的性能。蒸馏模型保留了迭代细化能力,同时需要更少的步骤来生成高质量结果。结果如图4-6所示。

图4. 使用 ADD 的 SD3.5 Large Turbo,分别使用 1 步、4 步和 10 步。

图5. SD3.5 Large 使用 1 步、10 步和 25 步,指导尺度为 3.5。

图6. SD3.5 Large 使用 1 步、10 步和 25 步,指导尺度为 7.0。
ADD 在训练期间使用两种损失函数:1)对抗性损失,通过训练模型欺骗判别器来确保输出位于真实图像的流形上;2)蒸馏损失,使用预训练的扩散模型作为教师,指导模型匹配去噪目标。Black Forest Labs 也贡献了开放权重的 FLUX.1 系列。FLUX.1 模型直接从非开放权重的 120 亿参数专业模型蒸馏而来。FLUX.1 [schnell] 使用 ADD,而 FLUX.1 [dev] 采用指导蒸馏来提高采样效率。
以下是运行 FLUX.1 [schnell] 的代码。该模型也是受限的,需要 Hugging Face 令牌访问。
import torch
from diffusers import FluxPipeline
pipe = FluxPipeline.from_pretrained("black-forest-labs/FLUX.1-schnell", torch_dtype=torch.bfloat16)
pipe = pipe.to("cuda")
prompt = "一块部分埋在沙漠中的古老石碑,黄昏时分,石碑上覆盖着发光的符号。碑文用符文和未来主义文字写着:'我们需要变换器来实现人工智能'。符号微微闪烁,在沙地上投下阴影。上方,一张半透明的卷轴展开,上面有更多神秘的符文,天空从粉红色过渡到紫色,地平线上有一个超现实的月亮。"
image = pipe(prompt).images[0]
imageADD 模型的结果,包括 SD3.5 Large Turbo 和 FLUX.1 [schnell],如图7所示。
FLUX.1 [dev] 应用指导蒸馏来提高无分类器指导模型的效率。这个两阶段过程首先训练学生模型以复制冻结教师模型的输出,然后逐步将学生蒸馏为需要更少采样步骤的版本(Meng 等人,2023)。FLUX.1 [dev] 的结果如图7所示。

图7. 对抗性扩散蒸馏模型的比较,包括 SD3.5 Large Turbo(左)和 FLUX.1 [schnell](中)。两个模型均在 A100 GPU 上使用 4 步推理、指导尺度为 0.0 和 bfloat-16 操作运行。FLUX.1 [dev] 使用 28 步和指导尺度为 7 运行(右)。
- 总结
带有变换器的扩散模型提高了类别标签引导图像生成的最新水平。修正流的进一步进展已应用于提高文本到图像生成的质量和采样效率。蒸馏的修正流变换器在少量采样步骤内提供了高度美观的结果。
- 参考文献按主题分类
扩散变换器(DiT)
Peebles 和 Xie,使用变换器的可扩展扩散模型,2023.
去噪扩散
Rombach 等人,使用潜在扩散模型的高分辨率图像合成,2022.
修正流变换器
Esser 等人,扩展修正流变换器用于高分辨率图像合成,2024.
修正流
Albergo 和 Vanden-Eijnden,使用随机插值构建归一化流,2023.
直接偏好优化
Raflailov 等人,直接偏好优化:你的语言模型实际上是一个奖励模型,2023.
Wallace 等人,使用直接偏好优化的扩散模型对齐,2023.
模型蒸馏
近期模型发布
介绍 Stable Diffusion 3.5(2024年11月访问).
宣布 Black Forest Labs(2024年11月访问).
- 附录
A. 近期和旧版模型的视觉比较
使用 Hugging Face Diffusers 库在 A100 GPU 上加载 16 位模型。推理使用 28 个采样步骤和指导尺度为 7 运行。生成每个图像面板的提示在本节末尾显示。
选择变换器结果,按模型大小从小到大排列。


stabilityai/stable-diffusion-3.5-large;总参数 81 亿。

black-forest-labs/FLUX.1-dev;总参数 120 亿;指导蒸馏。
选择旧版 U-Net 模型的结果,按模型大小从小到大排列。

stabilityai/stable-diffusion-2;总参数 8600 万加一个文本编码器。
FluxAI 中文
© 2026. All Rights Reserved