
ChatGPT-4o 能准确提供和解读广义线性模型的总结统计数据——…
将近 2 年前
ChatGPT-4o 可以正确提供和解释广义线性模型的摘要统计——但在其他方面你需要小心
在过去几周,我们研究了 ChatGPT-4o 在某些方面的可靠性。
我发现的一个问题是关于模型拟合和假设违反的诊断。许多时候,这些假设的违反是由于响应变量(因此也包括残差)不符合正态分布。解决这个问题的一种方法是使用 广义线性模型(GLM),假设响应变量符合 指数族 中的某种分布。当然,正态分布是其中之一,但还有一些其他常用的分布,比如用于计数数据的 泊松分布 和用于存在-缺失或比例数据的 二项分布。这些是学习研究生级生物统计学的下一个逻辑步骤,因此这是我在课堂上接下来教授的内容。在这篇文章中,我们将看到 ChatGPT-4o 在运行和解释 GLM 模型(包括泊松回归和逻辑回归)方面的可靠性。在向我的学生介绍并演示这些模型后,他们被分配了一个练习,以实践和展示他们对这些模型概念的理解。下面,我将用相同的作业测试 ChatGPT-4o。
在这个作业中,我们使用了一个新的数据集,详细记录了在阿根廷的不同地块上发现的四种不同鸟类的数量,以及每个地块的土壤特征,包括中细沙、泥土和有机物质的含量,以及地块的季节和横断面,以及该地块是否与河流相关。在作业中,我首先要求学生创建变量 N.succinea 的点图和直方图,该变量表示在每个地块上发现的 N. succinea 鸟的数量,并要求他们评估该变量是否符合正态分布。ChatGPT-4o 正确地复制了这些图形,尽管在风格上有些许差异,直方图的箱宽也不同。它还正确识别出该变量存在强烈的右偏,并指出该变量不符合正态分布。接下来,我要求学生和 ChatGPT-4o 创建一个散点图,y 轴为 N. succinea 鸟的数量,x 轴为中细沙的量(MedSand),并尝试从图中判断这两个变量之间是否存在显著关系。ChatGPT-4o 和一些学生一样,没有注意到这两个变量之间明显的(在我看来)负关系,并表示“似乎存在一个相对平坦的模式……,两个变量之间几乎没有可见的趋势或相关性。”
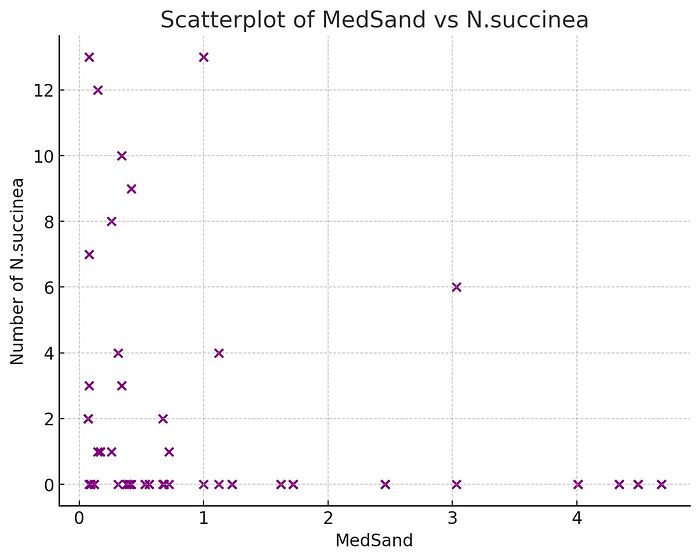
这是 ChatGPT-4o 提供的散点图
在这里,我要求学生和 ChatGPT-4o 进行泊松回归,使用 N.succinea 作为响应变量,MedSand 作为预测变量,汇总模型,并说明这两个变量之间是否存在显著关系。首先,分析因缺失值而出错,尽管数据集是完整的。在数据清理后(去除在导入数据时可能额外插入的 NAs),模型通过 Python 中的 statsmodels 包正常运行。报告的系数、标准误差、z 分数和 p 值对于斜率和截距都是与 R 提供的相同的,这很好。ChatGPT-4o 正确解释了负斜率系数和 p 值 < 0.001 作为这两个变量之间存在强烈负关系的证据。与学生一起,ChatGPT-4o 正确计算了泊松回归模型的准 R_平方,使用与 R 中相同的公式,并得到了 11.6% 的相同值,正确解释为解释的鸟类数量变化的一个小比例。ChatGPT-4o 还能够提取斜率系数的 95% 置信区间(CI),并正确诊断它不包含零,并理解这一事实与在显著性水平 0.05 下拒绝斜率为 0 的零假设检验的 p 值一致。虽然定性结果和解释是正确的,但 95% 置信区间的下限和上限的实际值与学生在 R 中获得的值并不相同。经过进一步深入研究,我了解到这是因为 R 使用 轮廓似然 来获得斜率系数的 95% 置信区间,而 Python 中的 statsmodels 包使用 Wald 近似,即简单地将标准误差乘以 1.96。虽然这要快得多,但准确性较差,特别是当响应变量不符合正态分布时,比如在运行 GLM 时。虽然在这种情况下,这只导致了定量而非定性差异,但可以想象,当 95% 置信区间的下限或上限非常接近 0 时,可能会导致定性不同的结果。再次强调,这不是 ChatGPT-4o 的问题,而是 Python 和 R 之间实现的差异,但很少有人意识到这一点(我之前也不知道)。
接下来,我要求 ChatGPT-4o 对斜率系数进行指数运算,并完成一个总结模型的句子,例如:
“对于 MedSand 每增加 1 个单位,N. succinea 的数量 _____ 乘以 _____。”
缺失的部分应该填入“变化”和斜率系数的指数。ChatGPT-4o 正确进行了指数运算,并在句子中填入了正确的数字,但在第一部分填入了“减少”而不是“变化”:
这个句子可以完成为:“对于 MedSand 每增加 1 个单位,N. succinea 的数量减少了 0.5246 倍。”
这使得结果句子有些令人困惑,尤其是因为接下来它继续说:
这意味着当 MedSand 增加 1 个单位时,预计的 N. succinea 数量减少了约 47.5%(因为 1–0.5246 ≈ 0.475)。
我必须承认,刚开始阅读时我非常困惑,因为这两个句子都包含“减少”这个词,但当然意味着不同的事情。在第一个句子中,当 MedSand 增加 1 个单位时,N. succinea 的数量乘以 0.5246 得到新值。在第二个句子中,它意味着当 MedSand 增加 1 个单位时,N. succinea 的新值比之前的值低 47.5%。这两个在数学上是相同的,但我花了一分钟,经过几次反复提问才理解这一点。
接下来,我要求学生和 ChatGPT-4o 创建一个效应图,以可视化这两个变量之间的关系,既在链接函数(log)尺度上,也在自然尺度上,显示最佳拟合回归线和 95% 置信带。在这里,真正的问题开始了,ChatGPT-4o 一再出错,无法完成图形。它会以以下方式结束尝试:
让我尝试一种简化的方法,以确保所有值都正确转换为图形。我会尽快解决这个问题。
也许我应该更有耐心,但我一直在催促它。我要求它简单地绘制一系列 MedSand 值的预测对数计数,而不带置信带。它成功绘制了图形,但显示的是预测计数,而不是对数计数。当我特别要求对这些进行自然对数运算时,它成功提供了正确的图形。然而,它无法在此图中添加 95% 置信带,出现了与之前效应图相同的问题,表明问题出在置信带上。接下来,我尝试手动构建预测表,从数据范围内的 MedSand 值序列开始,然后要求它将 N.succinea 的预测计数及其自然对数,以及这两个的 95% 置信区间的下限和上限添加到此表中。它正确地完成了这一任务。然后我询问这个表中是否有任何无穷大或 NA 值会干扰处理,因为错误消息提到在尝试添加置信带时提到“isfinite”命令。没有这样的值。然后我能够通过要求 ChatGPT-4o 一一绘制这些列来手动组装效应图。这是一个繁琐的变通方法,但它产生了与我在 R 中获得的相同图形。
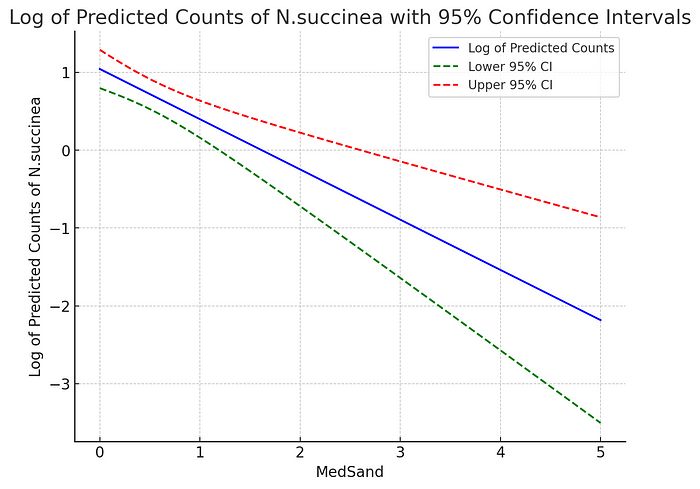
这是我与 ChatGPT-4o 手动拼凑在一起的效应图
接下来,我要求 ChatGPT-4o 在 y=0 处添加一条水平线,并询问它这条线是否与 95% 置信区间相交。我这样做是因为我教我的学生,如果你可以在效应图的范围内放置一条水平线,穿过 95% 置信带,这表明存在显著关系,并且斜率为零的零假设检验的 p 值应该小于 0.05。ChatGPT-4o 正确识别出这条线穿过了 95% 置信区间,但它提供了与我的解释不同的解释,认为 N. succinea 值的对数在 MedSand 的范围内接近 0,而这条线在置信带内(这是正确的)。然后我要求它移动这条水平线,首先移动到 N. succinea 的平均值的对数,它最初误解为平均预测计数的对数。我让它纠正为移动到 N. succinea 的观察值的平均值的对数,因为我预计那是 95% 置信带最窄的地方。结果并非如此,但我们一致认为所有回归线必须通过 x 和 y 的观察值的平均值。它试图检查这是否确实如此,并报告 x 和 y 的观察值和预测值的平均值不同。与其进一步深入这个问题,我让它将水平线移动到模型的截距值,并询问它是否与 95% 置信带相交,以及它将如何解释,但它没有给我我预期的解释。当我尝试提供我对这条水平线穿过置信带的解释,以及斜率的 p 值 <0.05 的事实时,它不同意我的解释。相反,它继续谈论我们可以使用斜率系数的 95% 置信区间(也许是因为我在提示中意外提到过这一点,而不是置信带)。当我询问我们是否可以通过视觉评估效应图来确定斜率系数的显著性时,它正确指出,如果我们可以在 95% 置信带中放置一条水平线并保持在其中,这表明斜率可能为零。然而,当询问在哪里放置这条水平线时,它建议 y=0,似乎在评估斜率的显著性时混淆了 95% 置信区间和在显示 95% 置信带的图中放置这条水平线。它在 y=0 处添加了水平线,并在 y=截距处添加了水平线(在询问后),并错误地表示 y=0 的线没有穿过 95% 置信区间。当我指出这一点时,它纠正了自己,但在图形的解释上变得非常困惑,似乎再次将其与斜率系数的 95% 置信区间混淆。当我指出这一点时,它承认了混淆,并放弃了在 y=0 处放置水平线,但仍然不同意我的解释,并且无法建议水平线的正确放置(我会放在响应变量的观察值的平均值处)。得出结论,我让 ChatGPT-4o 彻底困惑,我转而要求它基于手动组装的表格,在自然尺度上创建效应图。
接下来,我要求 ChatGPT-4o 创建一个新变量,以表示 N. succinea 鸟的存在或缺失。起初,它感到困惑,并在我之前要求它为效应图制作的预测表上进行了此操作。一旦我纠正它在原始数据上执行此操作,它就遵从了。它正确创建了这个新变量的散点图,y 轴为该变量,x 轴为 MedSand,但它再次未能在此图中视觉上发现这两个变量之间的关系,没有看到在 MedSand 高值下缺失的显著性。
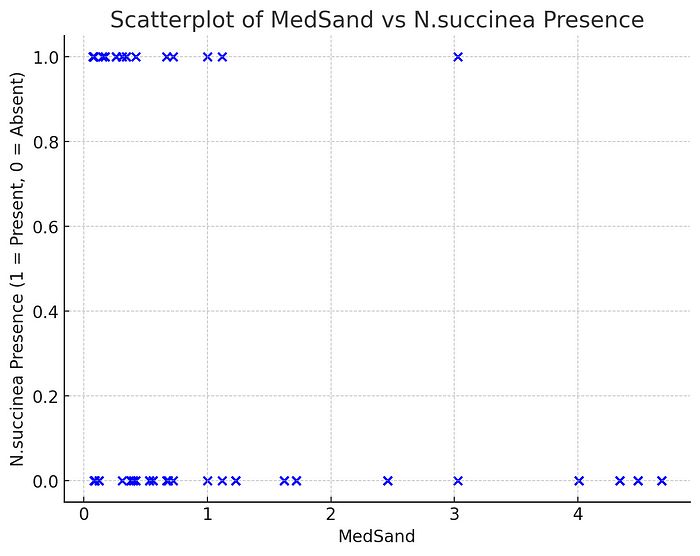
这是 N. succinea 存在/缺失与 MedSand 的散点图。
在被问及时,它能够正确运行逻辑回归,以 N. succinea 鸟的存在/缺失作为响应变量,MedSand 作为预测变量,经过几次缺失数据的波折,提供了斜率和截距系数的正确估计、标准误差、z 分数和 p 值。它正确解释了这两个变量之间显著的负关系,并且还进行了似然比检验(未提示)并正确解释了结果。它再次正确计算和解释了逻辑回归的准 R_平方,尽管使用了稍微修改的相同公式。它能够提取斜率系数的 95% 置信区间的下限和上限,并评估和解释该区间是否包含 0。与泊松回归一样,尽管定性结果是正确的,但实际值与 R 中获得的值不同,因为 Python 使用 Wald 近似,而 R 使用轮廓似然来获得它们。ChatGPT-4o 能够获得斜率系数的指数值,以及 95% 置信区间的下限和上限的指数值,并完成类似于我要求的泊松回归的句子,但对于 MedSand 增加 1 个单位时鸟类物种存在的几率,存在类似的语义问题。当被要求为逻辑回归创建效应图时,经过出错后,它能够为逻辑回归创建图形。然而,置信带看起来与 R 中生成的不同,并且似乎是对称的。
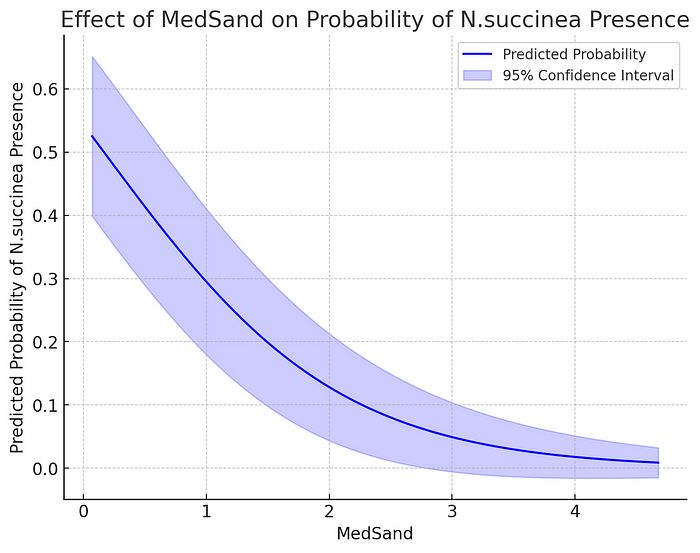
这是 ChatGPT-4o 生成的逻辑回归效应图,使用了正常近似。
在检查 Python 代码时,我发现使用正常近似来计算比例的标准误差。当我强调这一点时,ChatGPT-4o 承认使用了正常近似,并纠正为使用 logit 链接函数,但它仍然使用了不同的正常近似来计算对数几率的标准误差,导致生成的置信带仍然与 R 不同。最后,当我强调这一点时,它使用了估计参数的方差-协方差矩阵来获得更精确的预测概率的标准误差,生成的置信带现在看起来与 R 的结果完全相同。
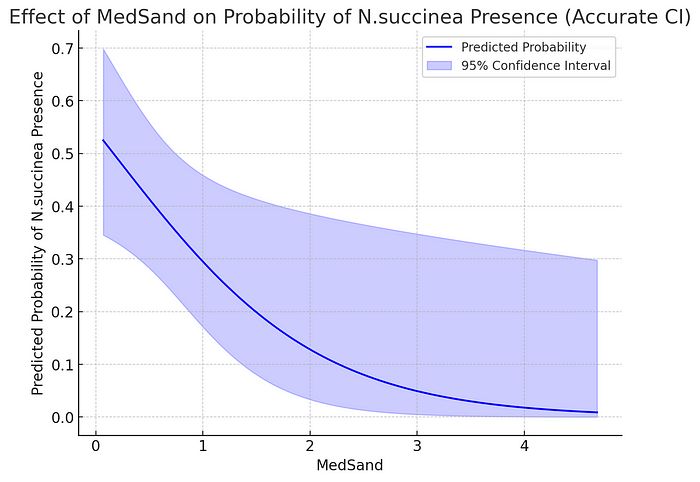
这是 ChatGPT-4o 生成的逻辑回归的正确效应图。
我也能够让它在对数几率尺度上做到这一点。当我要求它在此图中添加一条在 MedSand 范围内始终保持在 95% 置信带内的水平线时,它尝试这样做,并放置了一条水平线,它说始终保持在置信带内,但实际上并没有。当我指出这一点时,它承认了错误,尝试再次放置,并放置了另一条水平线,可能是最接近完全在 95% 置信带内的那条线,但在极端情况下仍然穿过了置信带,而它没有意识到。当我指出这一点时,它再次承认错误,并表示可能没有这样的线。当我询问这是否是两个变量之间显著关系的视觉证据时,它现在同意了。
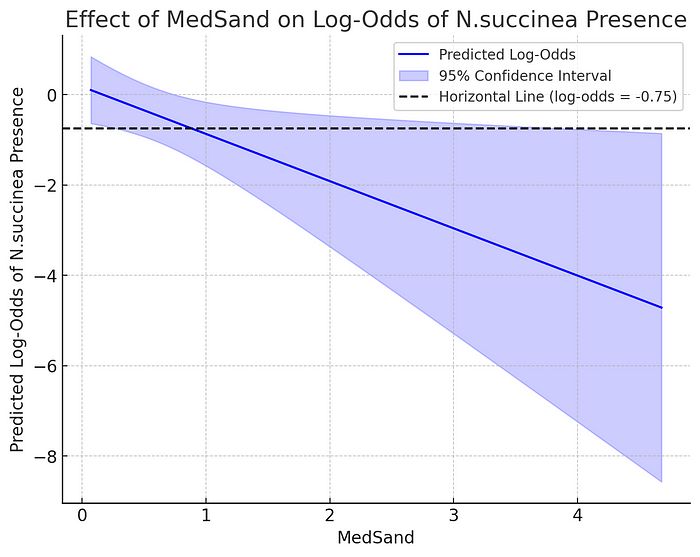
这是 ChatGPT-4o 添加的水平线的对数尺度效应图,尽管它并没有始终保持在置信带内。
最后,我询问了用于 GLM(如逻辑回归)的诊断方法。与线性回归使用的 尺度-位置图 和 qq 图 不太相关,但 GLM 仍然有假设(如独立性、均值与方差之间的特定关系、预测变量的线性等)可能会被违反。当询问如何诊断模型时,它确实提供了一些建议,例如残差分析。在经过几次波折后,它确实生成了一些看起来合理的残差图(不再与 R 比较),并提供了合理的解释。我可能会在 R 中重新创建这些图,以为我的学生提供更多诊断 GLM 模型的工具。最后,我深入了解了 Python 和 R 在如何估计斜率系数的 95% 置信区间方面的差异。我了解到 statsmodels 包没有内置的函数来进行轮廓似然,而 R 中的 confint() 命令可以做到。虽然在 Python 中可以通过暴力方法实现,但这对 ChatGPT-4o 来说在会话中太复杂。虽然 ChatGPT-4o 能够解释轮廓的工作原理(基本上就是获取不同模型在一定似然比区间内的不同斜率系数的似然),但在尝试实现该方法时遇到了奇异性问题。它建议使用自助法作为替代方法,这有效,但导致非常宽的 95% 置信区间。在讨论 Wald 近似和轮廓似然之间的差异时,它承认 Wald 方法可能存在偏差,部分原因是其对称性,并且对假设的违反(特别是正态性和同方差性)更敏感,这在使用 GLM 时相当常见。不幸的是,基于这些,很难证明使用 Wald 置信区间而不是轮廓似然置信区间,除非它们提供定性相似的结果,当然我们无法仅通过 Python 或 ChatGPT-4o 来看到这一点,因为我们无法进行比较。然而,显然即使在 R 中,效应图也使用 Wald 近似来获取 95% 置信带,因此这种差异仅在评估斜率系数的 95% 置信区间时才重要。我甚至与 ChatGPT-4o 进行了长时间的讨论,关于效应图是如何创建的,以及为什么置信带可能是不对称的,以及预测值的标准误差与斜率的标准误差之间的关系,以及预测变量在给定区域中的值数量如何影响这一点。
当我尝试复制上述实验时,我一次性复制了所有指令。虽然所有输出都是相同的,但 ChatGPT-4o 在尝试为泊松回归创建效应图时再次出错,需要提示才能继续进行逻辑回归,这再次产生了一致的结果。ChatGPT-4o 能够创建效应图(甚至在未提示的情况下添加观察点),但只添加了估计的最佳拟合线。当我要求它添加 95% 置信区间时,它再次出错。在多次尝试后,它提到“fill_between”函数作为错误的来源,以及数据如何传递给它。这个函数在图形上填充多边形或形状。当我要求创建不使用“fill_between”的效应图时,它成功了!因此,当你尝试让 ChatGPT-4o 为你的模型创建效应图时,请尝试在提示中添加这一点。如果它能让我免于手动创建预测表,并让 ChatGPT-4o 绘制每条线,那么我不介意没有用颜色填充的置信带。
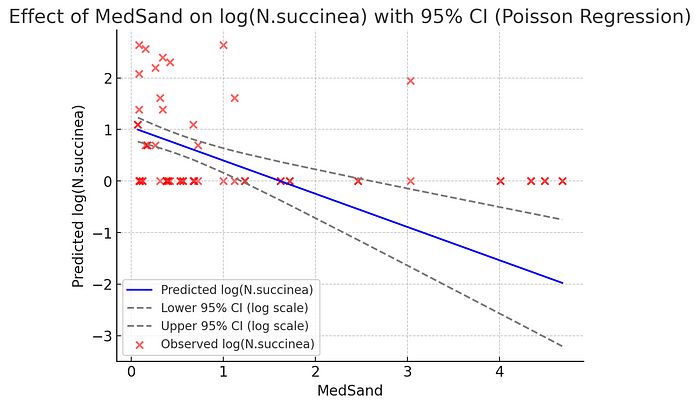
这是 ChatGPT-4o 为泊松回归创建的对数尺度效应图,指定不使用“fill_between”。置信区间似乎与 R 输出一致。
总之,ChatGPT-4o 确实可以通过 Python 运行广义线性模型。它确实得到了正确的估计和 p 值,并能够正确解释它们。然而,它只能为斜率系数提供 Wald 置信区间,而不是我们在 R 中获得的轮廓似然置信区间。这可能会误导并潜在地危险,因为不熟悉差异的人可能会将其视为理所当然。它在创建效应图方面也存在困难,尽管通过要求它不使用“fill_between”命令可以缓解这一问题。如果它尝试自己计算置信区间,它可能还会使用正常近似来计算估计值或预测值的标准误差,而不是使用估计参数的方差-协方差矩阵,正如 Python 中的 statsmodels 包或 R 中的 glm 所做的那样。这些不准确的标准误差将传播到 95% 置信带中,产生不准确的效应图。这些差异对于即使是具有适度统计经验的人(例如我班上的研究生)来说也难以识别,尤其是在没有正确图形进行比较的情况下。ChatGPT-4o 在评估自己创建的图形上的模式方面仍然存在不足,例如在散点图中判断两个变量之间是否存在关系,或者一条线是否穿过 95% 置信带。我还能够让它彻底困惑关于斜率系数的 95% 置信区间与我们是否可以使用效应图来评估斜率在 0.05 水平上显著性的区别,基于一条水平线(在响应变量的观察均值处)是否穿过 95% 置信带。基于所有这些,我可以推荐使用 ChatGPT-4o 来运行和解释广义线性模型的摘要统计。我可以推荐使用它提供的 95% 置信区间,但要理解这些是 Wald 置信区间。我只会依赖 ChatGPT-4o 获取准确的效应图,前提是仔细检查 Python 代码,以确保它使用了正确的方法。最后,我不会依赖它对其提供的图形进行视觉解释——我会自己查看它们。我们人类在模式识别方面仍然远胜于 ChatGPT-4o,至少在这些图形上是如此。
FluxAI 中文
© 2026. All Rights Reserved