
你能信任AI来总结重要文件吗?
超过 1 年前
你可以信任人工智能总结重要财务报告吗?
而且你能给出一个从1到10的评分吗?
在本文中:
- 挑战是什么?关键角色是谁?
- 什么是一个好总结的简洁定义
- 如何制定衡量总结信息量的指标。
 图片来源:https://images.app.goo.gl/vUK5bAqzY9DAzUys9
图片来源:https://images.app.goo.gl/vUK5bAqzY9DAzUys9
挑战是什么?关键角色是谁?
想象一下,你是一名金融分析师、交易员或投资者,需要为自己或客户做出快速、明智的决策。你采取了正确的方法——分析公司的公开财务报告和来自可信来源的相关新闻。
但现实是:这些报告很长、内容复杂,需要大量的专业知识和时间才能提取出有意义的见解。
举个例子,考虑一下SEC 10-Q和10-K报告,这是上市公司提交的官方季度和年度财务报表。平均而言:
- 10-Q报告大约有80页长。
- 10-K报告的长度从150到300页不等。
现在,想象一下分析10家不同的公司——信息量庞大得让人难以承受。如何在不花费无数小时的情况下高效提取关键见解呢?
< <注意>> 这是我第一篇关于这个主题的文章的改进版,原文刊登在Substack的Betaflow-AI期刊。我将把链接留在本文脚注部分¹。
什么定义了一个“好”的总结?
现在我们对问题有了一些“感觉”,让我们回到基础:什么是好总结的定义?基于明确的定义,我们可以
- 设置对好总结的预期
- 制定衡量总结质量的指标。
让我们参考剑桥词典的定义:
总结:一个简短、清晰的描述,提供关于某事的主要事实或想法。
让我们来拆解这个定义,以尝试对其进行“量化”。这种拆解将帮助我们理解用来评估总结质量的各种指标的制定。
量化总结质量:拆解
为了更好地了解总结质量是如何评估的,让我们对其定义进行量化。这种拆解将帮助我们掌握各种指标的制定。
1. 简短描述
根据定义,总结的长度应该明显短于原始文档。如果我们将其定义为:
- L_s:总结中的单词数
- L_w:原始文档中的单词数
那么,这个关系应该成立:L_s << L_w。
2. 主要事实和想法
高质量的总结应尽可能捕捉有用且相关的信息,同时保持较短的长度。挑战在于保留关键信息而丢弃不必要的细节。
3. 与决策相关的总结(技术说明)
在许多情况下,摘要应该针对特定决策量身定制。如果我们事先知道基于总结将做出什么决策,记录的过程就可以优化,突出决策相关的信息,而不仅仅是一般的有用内容。
ROUGE指标——它是什么?
评估生成文本摘要的最简单但有效的指标之一是ROUGE:以召回为导向的简述评估。计算ROUGE指标的过程可以在下图中总结
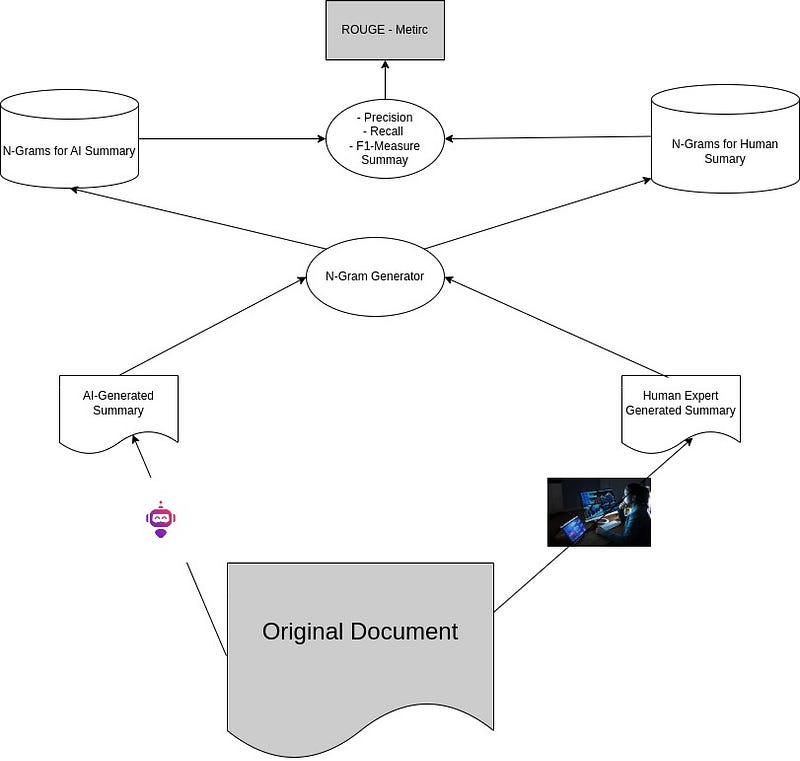 ROUGE计算过程
ROUGE计算过程
- 摘要生成:对于给定文档,生成机器摘要(在这种情况下是大型语言模型生成的),并生成由人类领域专家完成的参考摘要。
- N-Gram生成器:N-Gram是对句子中1、2或N个标记的分组。它们是捕捉文本结构的基本方法。例如,对于句子“I love dogs”,1-Gram是:I, love, dogs。2-Gram是:I love, love dogs。3-Gram是:I love dogs。
- 精确度 / 召回率 / F1度量计算:
 ROUGE-计算
ROUGE-计算
召回率:人类摘要中的共同N-Gram数量 / 人类摘要中的N-Gram数量
精确度:人工智能摘要中的共同N-Gram数量 / 人工智能摘要中的N-Gram数量
F1分数:结合精确度和召回率的一种方式,可以计算为
2 * (精确度 * 召回率) / (精确度 + 召回率)
这三个分数构成了ROUGE指标。
在下一篇文章中,我将展示一个使用大型语言模型评估财务10K报告摘要的实际案例,敬请期待!
如果你喜欢这篇文章并希望收到类似的内容:
- 点赞并留言你对这篇文章的想法
如果你对如何应用大型语言模型解决商业问题有任何问题,请发送电子邮件至betaflowcompany@gmail.com。
参考资料
推荐阅读:





FluxAI 中文
© 2026. All Rights Reserved