
AI创新与洞察18:GARLIC,你了解多少?
超过 1 年前
这篇文章是这个引人入胜的系列中的第18篇。
从个人兴趣的角度来看,我一直对数据结构非常着迷,正如你在我之前的文章中看到的那样。这也是为什么我会特别关注那些结合了高级数据结构的RAG系统。
今天,我们将讨论GARLIC,它完美地体现了这一特点。
视频中包含了一个思维导图:
生动的描述
想象你在一家图书馆里,试图从一本1000页的书中找到最重要的信息——比如每个角色的旅程和关键情节。传统的方法可能会让你感觉像是在和两个笨拙的助手一起工作:
- 助手A(传统的RAG)把书一页一页地剪成碎片,然后根据关键词随机递给你一些页面。但他无法解释这些页面如何相互关联或它们的上下文。
- 助手B(基于树的RAG)把书变成一棵树,一次只搜索一个分支。如果你需要从另一个分支找东西,他必须爬回顶部重新开始,浪费了大量时间。
现在,想象一下像GARLIC这样的“智能图书管理员”:
- 他创建了书的层次结构图,突出显示关键事件和关系,让你看到一切是如何连接的。
- 当你提出一个问题时,比如“主角经历了什么?”他会快速导航到最相关的路径,并给你一个清晰简洁的答案。
- 他知道何时停止,这样你就不会陷入无休止的搜索中。
这种方法帮助GARLIC在更短的时间内给你更准确、全面的答案。
现在,让我们深入了解一下详细的内容。
背景
在长文档问答(QA)领域,检索增强生成(RAG)方法一直占据主导地位。这些方法将长文本分割成较小的块,并检索相关的片段输入到LLM中。
然而,RAG存在一些关键的限制:
- 全局上下文丢失:块通常会丢失整体上下文,这对于需要跨多个事件连接的复杂查询至关重要。
- 密集嵌入:传统的RAG方法依赖于密集嵌入来计算节点的相关性,但这种方法还有改进的空间。
- 检索效率低下:像RAPTOR和MeMWalker这样的基于树的RAG方法在处理刚性单路径遍历时表现不佳,限制了它们的灵活性。
- 计算开销:直接将长文本输入到高级LLM(如Llama 3.1)中计算成本很高,特别是对于超过100K token的输入。
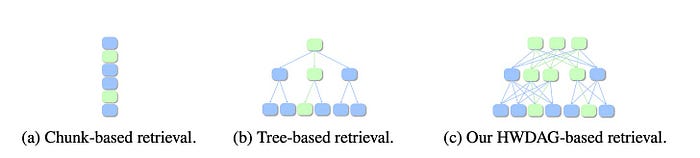
图1:三种检索方法的比较。绿色阴影的节点是检索到的节点。(a)基于块的检索。(b)基于树的检索,从顶部节点开始,每层选择一个子节点,直到到达底部节点。(c)基于HWDAG的检索。节点搜索是灵活的,允许多条路径从顶层开始,并且搜索可以在任何层级停止。来源。
例如,想象你正在搜索一本1000页小说中的关键事件。传统的RAG方法只能给你孤立的段落,RAPTOR将你的搜索限制在一个固定的故事线上,而将整本小说输入到LLM中会消耗大量的GPU资源。
如果我们能动态地找到最关键的信息,像智能图书管理员一样灵活地导航内容呢? 这就是GARLIC背后的核心理念。
GARLIC
如图2所示,GARLIC引入了LLM引导的动态进度控制,使用层次加权有向无环图(HWDAG),这是一种基于图的检索方法。
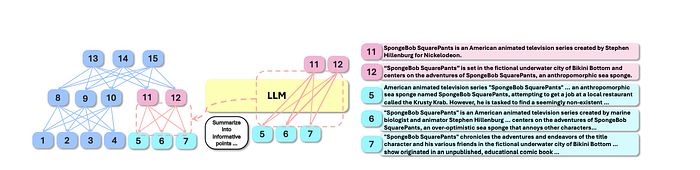
图2:层次加权有向无环图的概述,用于摘要。来源。
GARLIC的关键创新点:
- 构建一个图,其中每个节点代表一个信息点(IP),总结细粒度的事件。
- 使用LLM的注意力权重进行节点遍历,而不是密集嵌入。
- 动态控制检索过程,在收集到足够信息时停止。
这种方法确保需要详细或全局上下文的查询能够高效处理,而无需不必要的计算。
关键步骤
GARLIC的操作分为两个主要阶段:
1. 摘要图构建:
- 输入文档被分割成块(300个token)。LLM将这些块总结为要点信息点(IPs)。
- 如图2所示,摘要过程递归进行,形成一个多层次的HWDAG,其中:节点代表总结事件的IPs。边使用LLM注意力分数加权,捕捉IP之间的关系。
- 每个节点专注于单个事件,实现细粒度检索。
示例:想象一本书被总结为一个层次图。每个要点摘要(IP)是一个节点,而边代表一个摘要与另一个事件的连接强度。
2. 动态图搜索:
- 通过贪心最佳优先搜索(GBFS)检索节点并输入到LLM中。
- LLM检查是否有足够的节点来回答查询,通过KV缓存实现,无需额外成本。一旦收集到足够的节点,生成最终答案。
- 它在遍历过程中使用LLM注意力权重,而不是密集嵌入,提高了准确性。
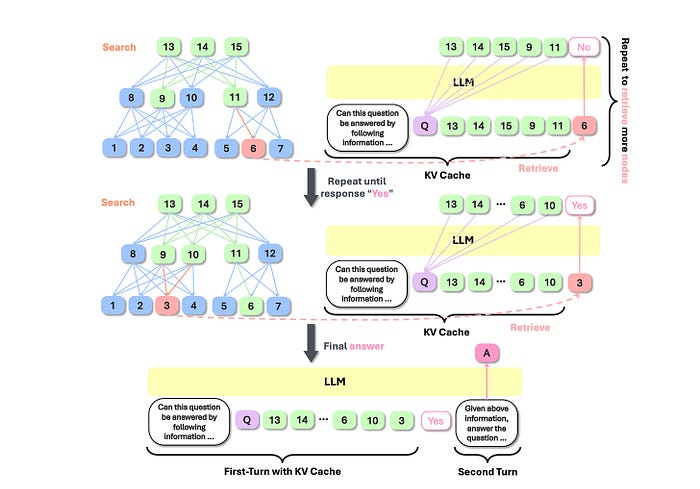
图3:动态图搜索的概述。[来源]。
评论
从GARLIC的算法中,我有以下见解:
- 基于图的检索可能是处理长文档的关键方向。
- 基于注意力权重的检索可能在更广泛的场景中探索。
尽管GARLIC具有创新性,但在我看来,仍然存在一些挑战:
- 注意力分数归一化使用经验方法,可能在不同上下文中不一致。
- 动态搜索停止机制依赖于LLM对“足够信息”的判断,但这因查询复杂性而异,可能导致复杂任务中过早或过晚停止。
- 虽然HWDAG的多路径检索提供了全面的覆盖,但路径重叠可能会在没有明确冗余处理的情况下浪费计算资源。
- 图构建需要通过逐层摘要进行密集的预处理,对于大文档来说计算成本很高。此外,当文档发生变化时,它似乎缺乏增量更新的能力。
最后,如果你对这个系列感兴趣,欢迎探索我的其他文章。
油管。FluxAI 中文
© 2026. All Rights Reserved